linux
Eclipse
程序人生
CTF
华为机试
.netcore
科技
SAP ABAP
flink 最后一个窗口
秒掉
NPDP
考试管理系统
adb
AI二次开发
栈
activity7
网站漏洞修复
互联网
虚拟主机
信息系统项目管理师
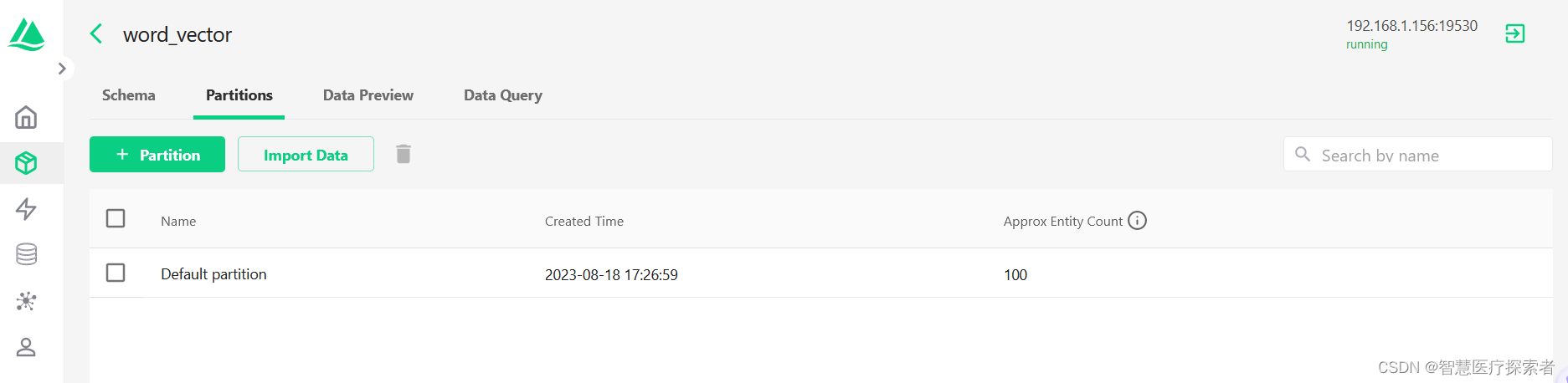
Milvus
2024/4/12 13:35:14
应对数据爆炸时代,揭秘向量数据库如何成为AI开发者的新宠,各数据库差异对比
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…

milvus数据库-管理数据库
一个 Milvus 集群最多支持 64 个数据库。
1.创建数据库 先连接数据库服务器,再创建
from pymilvus import connections, dbconn connections.connect(host"127.0.0.1", port19530)database db.create_database("book")2.连接数据库 可以改变…
Milvus向量数据库基础用法及注意细节
1、Milvus数据类型与python对应的数据类型 Milvus Python DataType.INT64 numpy.int64 DataType.INT32 numpy.int32 DataType.INT16 numpy.int16 DataType.BOOL Boolean DataType.FLOAT numpy.float32 DataType.DOUBLE numpy.double DataType.ARRAY list DataT…

《向量数据库》——向量数据库Milvus Cloud 和Dify比较
Zilliz Cloud v.s. Dify Dify 作为开源的 LLMs App 技术栈,在此前已支持丰富多元的大型语言模型的接入,除了 OpenAI、Anthropic、Azure OpenAI、Hugging face、Replicate 等全球顶尖模型及模型托管平台,也完成了国内主流的各大模型支持&#…
ModaHub魔搭社区:向量数据库Milvus性能优化问题(一)
目录
性能优化问题
为什么重启 Milvus 服务端之后,第一次搜索时间非常长?
为什么搜索的速度非常慢?
如何进行性能调优?
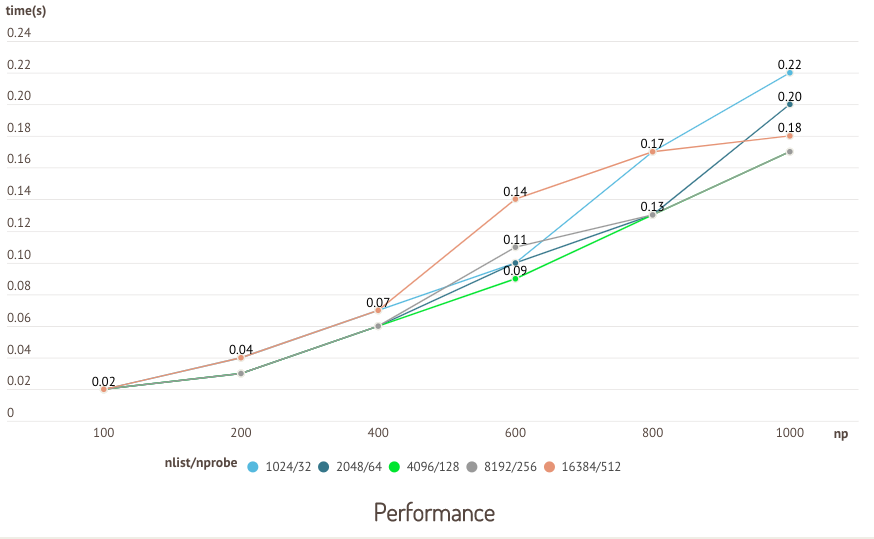
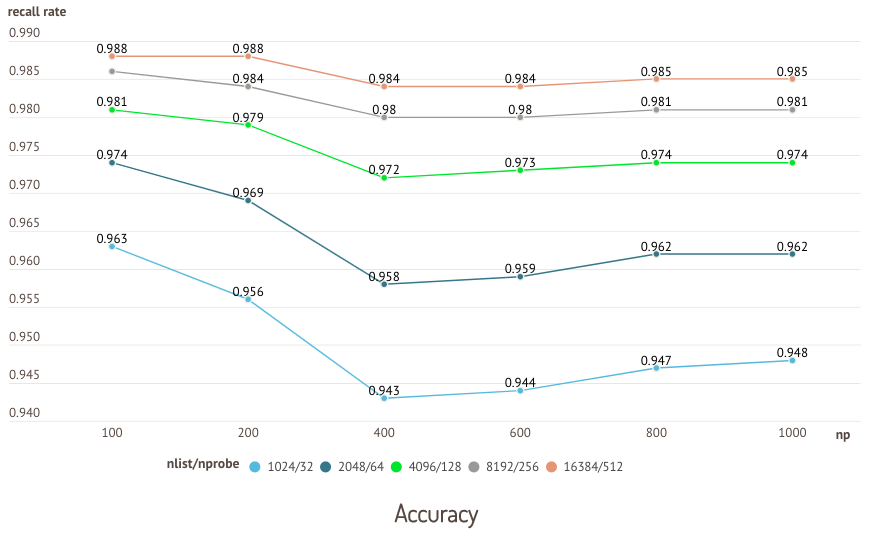
应如何设置 IVF 索引的 nlist 和 nprobe 参数? 性能优化问题
为什么重启 Milvus 服务端之后…
源码编译部署篇(二)源码编译milvus成功后如何启动standalone并调试成功!
Milvus启动和调试 0 前言1 Milvus启动【问题描述】出现Aborted问题【问题分析】【解决方法】安装Pulsar服务执行单机启动命令解决监听端口号 2 Milvus调试编写launch.json验证单例调试成功 3 遇到的问题汇总问题1问题2:Permission denied 0 前言
由于Milvus官方文档只提及如何…

《低代码指南》——如何用维格表搭建CRM
信息 手机上就能随时随地记录客户信息更智能地进行部门协作、沟通让每一项客户沟通都有迹可循一个表格实现客户全生命周期管理企业如何在激烈的市场竞争中崭露头角,拥有自己的立足之地,CRM 系统必然是一大助力。但传统 CRM 系统功能太多太复杂,不够灵活,内部推广、维护又很…
有了Milvus Cloud向量数据库,我们还需 SQL 数据库吗?
“除了向量数据库外,我是否还需要一个普通的 SQL 数据库?” 这是我们经常被问到的一个问题。如果除了向量数据以外,用户还有其他标量数据信息,那么其业务可能需要在进行语义相似性搜索(https://zilliz.com.cn/glossary/%E8%AF%AD%E4%B9%89%E6%90%9C%E7%B4%A2-%EF%BC%88sem…
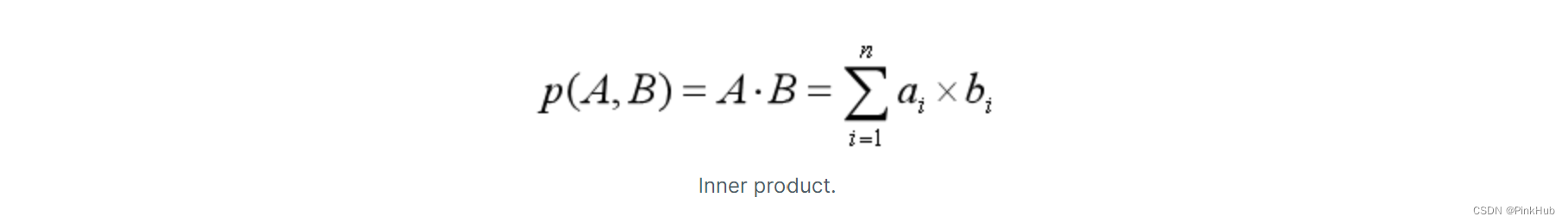
Milvus向量数据库
Milvus vector database
第一章 Milvus概述
Milvus创建于2019年,唯一的目标是:存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大量嵌入向量embedding vectors。
存储对象:向量
NOTE:embedding vectors是对非结构…

Elastic Cloud v.s. Zilliz Cloud:性能大比拼
Elastic Cloud v.s. Zilliz Cloud:性能大比拼 Zilliz 经常会收到来自开发者和架构师的提问:“Zilliz Cloud 和 Elastic Cloud 比起来,谁进行向量处理能力比较强?” 诸如此类的问题很多,究其根本,大都是开发者/架构师在为语义相似性检索系统进行数据库选型时缺少决策依据有…
milvus数据库搜索
一、向量相似度搜索 在Milvus中进行向量相似度搜索时,会计算查询向量和集合中具有指定相似性度量的向量之间的距离,并返回最相似的结果。通过指定一个布尔表达式来过滤标量字段或主键字段,您可以执行混合搜索。
1.加载集合 执行操作的前提是…
向量检索库Milvus架构及数据处理流程
文章目录 背景milvus想做的事milvus之前——向量检索的一些基础近似算法欧式距离余弦距离 常见向量索引1) FLAT2) Hash based3) Tree based4) 基于聚类的倒排5) NSW(Navigable Small World)图 向…
【腾讯云云上实验室-向量数据库】Tencent Cloud VectorDB在实战项目中替换Milvus测试
为什么尝试使用Tencent Cloud VectorDB替换Milvus向量库?
亮点:Tencent Cloud VectorDB支持Embedding,免去自己搭建模型的负担(搭建一个生产环境的模型实在耗费精力和体力)。
腾讯云向量数据库是什么?
腾…

《向量数据库指南》——向量数据库Milvus Cloud搭建Excel公式编辑器助手
引言
在日常工作中,Excel是我们经常使用的办公工具,而熟练应用Excel公式对于提高工作效率非常重要。然而,有时候我们会遇到一些复杂的需求,需要用到较为专业的Excel公式,而这正是Excel公式编辑器助手的用武之地。本文将介绍如何利用向量数据库Milvus Cloud搭建GPT大模型和…
《向量数据库指南》——向量数据库Milvus Cloud搭建Excel公式编辑器助手
引言
在日常工作中,Excel是我们经常使用的办公工具,而熟练应用Excel公式对于提高工作效率非常重要。然而,有时候我们会遇到一些复杂的需求,需要用到较为专业的Excel公式,而这正是Excel公式编辑器助手的用武之地。本文将介绍如何利用向量数据库Milvus Cloud搭建GPT大模型和…
安装向量数据库milvus及其Attu
前置条件安装docker compose
在宿主机上创建文件目录
mkdir -p /home/sunyuhua/milvus/db
mkdir -p /home/sunyuhua/milvus/conf
mkdir -p /home/sunyuhua/milvus/etcd下载docker-compose.yml
wget https://github.com/milvus-io/milvus/releases/download/v2.2.11/milvus-s…
《向量数据库指南》——LlamaIndex 和 Milvus Cloud对于 Chat Towards Data Science 的作用
那么,LlamaIndex 是如何帮助我们协调数据检索?Milvus 又如何帮助搭建聊天机器人的呢?我们可以用 Milvus 作为后端,用于 LlamaIndex 的持久性向量存储(persistent vector store)。使用 Milvus Cloud 实例后,可以从一个 Python 原生且没有协调的应用程序转换到由 LlamaIn…
milvus学习(一)cosin距离和欧式距离
参考:https://blog.csdn.net/qq_36560894/article/details/115408613 归一化以后的cosin距离和欧式距离可以相互转化,未归一化的不可以相互转化(因为距离带单位)。
milvus和相似度检索
流程
milvus的使用流程是 创建collection -> 创建partition -> 创建索引(如果需要检索) -> 插入数据 -> 检索 这里以Python为例, 使用的milvus版本为2.3.x 首先按照库, python3 -m pip install pymilvus
Connect
from pymilvus import connections
c…

《向量数据库》——Zilliz X Dify.AI ,快速打造知识库 AI 应用
Zilliz 大模型生态矩阵再迎新伙伴!近日,Zilliz 和 Dify.AI 达成合作,Zilliz 旗下的产品 Zilliz Cloud、Milvus 与开源 LLMOps 平台 Dify 社区版进行了深度集成。 01.
Zilliz Cloud v.s. Dify Dify 作为开源的 LLMs App 技术栈,在此前已支持丰富多元的大型语言模型的接入,…
milvus集合管理
一、创建集合
集合由一个或多个分区组成。在创建新集合时,Milvus会创建一个默认分区_default 1.准备模式 需要创建的集合必须包含一个主键字段和一个向量字段。INT64和String是主键字段支持的数据类型。
首先,准备必要的参数,包括字段模式、…
milvus数据库的数据管理-插入数据
一、插入数据
1.准备数据
数据必须与数据库中定义的字段元数据一致,与集合的模式匹配
import random
data [[i for i in range(2000)],[str(i) for i in range(2000)],[i for i in range(10000, 12000)],[[random.random() for _ in range(2)] for _ in range(2…

智源发布最强开源可商用中英文语义向量模型 BGE,超越同类模型,解决大模型制约问题
0.介绍
语义向量模型(Embedding Model)已经被广泛应用于搜索、推荐、数据挖掘等重要领域。
在大模型时代,它更是用于解决幻觉问题、知识时效问题、超长文本问题等各种大模型本身制约或不足的必要技术。然而,当前中文世界的高质量语义向量模型仍比较稀缺,且很少开源。
为…

ModaHub魔搭社区:向量数据库Milvus性能优化问题(三)
目录
Milvus 的导入性能如何?
边插入边搜索会影响搜索速度吗?
批量搜索时,用多线程的收益大吗?
为什么同样的数据量,用 GPU 查询比 CPU 查询慢? Milvus 的导入性能如何?
客户端和服务端在同…

用向量数据库Milvus Cloud搭建GPT大模型+私有知识库的定制商业文案助手
随着智能助手的不断普及和发展,商业文案的创作也变得更加智能化和定制化。在这个信息爆炸的时代,商业文案的撰写已经不再是简单的文字表达,而是需要结合大数据分析和人工智能技术,以更好地满足目标客群的需求。在本文中,我们将介绍如何利用向量数据库Milvus Cloud搭建GPT大…
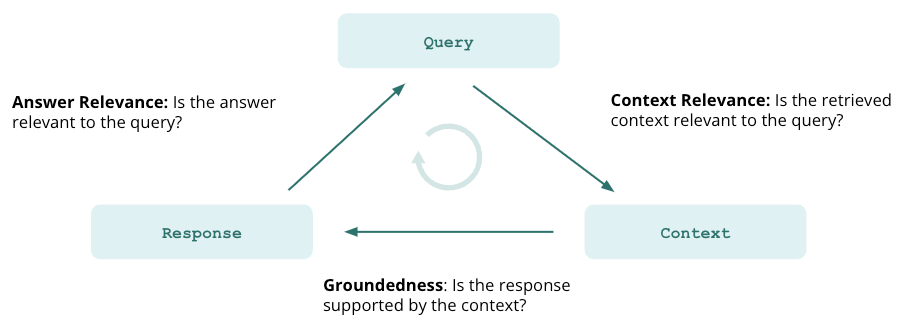
《向量数据库指南》——TruLens 用于语言模型应用跟踪和评估
TruLens 用于语言模型应用跟踪和评估 TruLens 是一个用于评估语言模型应用(如 RAG)的性能的开源库。通过 TruLens,我们还可以利用语言模型本身来评估输出、检索质量等。 构建语言模型应用时,多数人最关心的问题是 AI 幻觉(hallucination)。RAG 通过为语言模型提供检索上下文…

向量数据库库Milvus Cloud2.3 技术选型中性能、成本、扩展性是重点
技术选型中性能、成本、扩展性是重点 对于向量数据库来说,用户最关心的莫过于性能、成本和扩展性。 Milvus 2.x 从 Day 1 开始就将扩展性作为设计的第一优先级,在众多用户环境中落地了十亿至百亿级别场景。不止如此,对于 Milvus 来说,扩展性不仅仅意味着支持百亿级别向量,…

ModaHub魔搭社区:向量数据库Milvus产品问题(二)
目录
为什么向量距离计算方式是内积时,搜索出来的 top1 不是目标向量本身?
对集合分区的查询是否会受到集合大小的影响,尤其在集合数据量高达一亿数据量时?
如果只是搜索集合中的部分分区,整个集合的数据会全部加载…
ModaHub魔搭社区:向量数据库功能主要特点和应用场景
目录
主要特点
向量数据库功能
高性能向量搜索
低延迟高召回率
多向量搜索索引
向量数据库可以帮助的领域
图像相似性搜索
视频相似性搜索
音频相似性搜索 主要特点 向量数据库功能
高性能向量搜索
存储、索引和管理由深度神经网络和其他机器学习(ML&…
Docker【部署 04】Docker Compose下载安装及实例Milvus Docker compose(CPU)使用说明分享
Docker Compose 下载安装使用说明 1.Compose说明1.1 Overview of installing Docker Compose1.2 Installation scenarios1.2.1 Scenario one: Install Docker Desktop1.2.2 Scenario two: Install the Compose plugin1.2.3 Scenario three: Install the Compose standalone 2.C…
一文详解向量数据库Milvus Cloud动态 Schema
在数据库中,Schema 常有,而动态 Schema 不常有。 例如,SQL 数据库有预定义的 Schema,但这些 Schema 通常都不能修改,用户只有在创建时才能定义 Schema。Schema 的作用是告诉数据库使用者所希望的表结构,确…
利用Milvus Cloud和LangChain构建机器人:一种引人入胜且通俗易懂的方法
一、引言
机器人已经深入我们的日常生活,从家庭服务到工业生产,再到医疗和运输等领域。然而,这些机器人往往需要复杂的算法和数据处理技术才能有效地执行任务。在这个过程中,人工智能(AI)和机器学习&#…
向量检索:基于ResNet预训练模型构建以图搜图系统
1 项目背景介绍
以图搜图是一种向量检索技术,通过上传一张图像来搜索并找到与之相关的其他图像或相关信息。以图搜图技术提供了一种更直观、更高效的信息检索方式。这种技术应用场景和价值非常广泛,经常会用在商品检索及购物、动植物识别、食品识别、知…
ModaHub魔搭社区:Milvus 数据迁移工具 – MilvusDM
目录
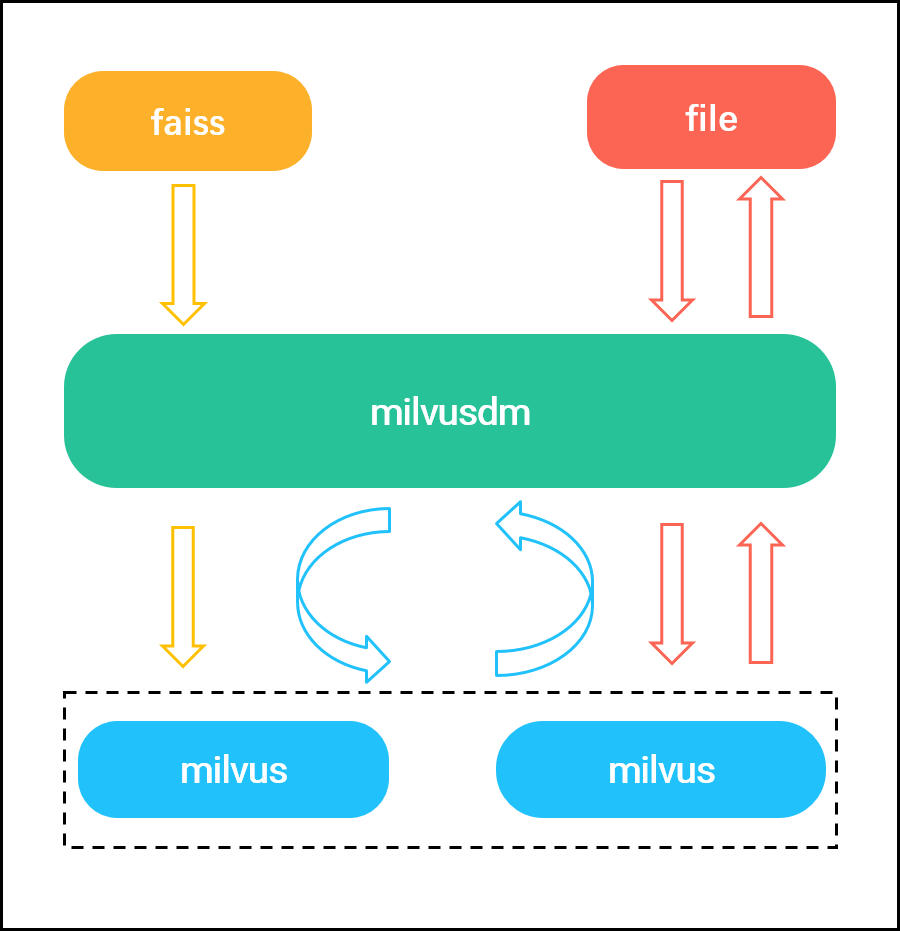
Milvus 数据迁移工具 — MilvusDM
简介
功能介绍
Faiss to Milvus Milvus 数据迁移工具 — MilvusDM
简介
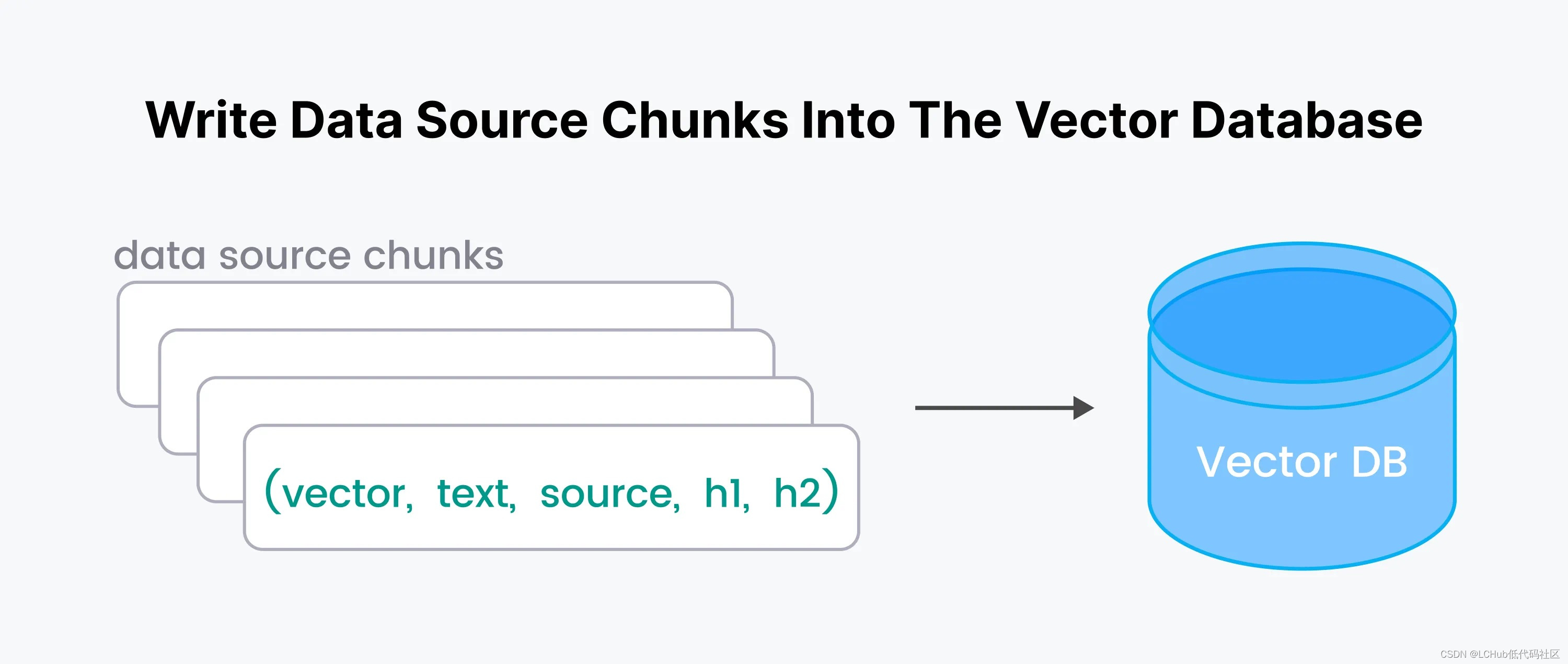
MilvusDM 是一款针对 Milvus 研发的数据迁移工具,支持 Milvus 数据传输以及数据文件的导入与导出:
Faiss to Milvus:将未…

CNCC 2023收官,Milvus Cloud与行业大咖共话向量数据库系统
近期,CNCC 2023 在沈阳圆满结束,紧凑、前沿的 129 场技术论坛让人印象深刻。据悉,这 129 场技术论坛涵盖人工智能、安全、计算+、软件工程、教育、网络、芯片、云计算等 30 余个方向。Zilliz 受邀参与【智能时代的大数据系统】技术论坛。 智能时代的到来,无疑给社会经济和日…

手把手教你用 Milvus 和 Towhee 搭建一个 AI 聊天机器人
作为向量数据库的佼佼者,Milvus 适用于各种需要借助高效和可扩展向量搜索功能的 AI 应用。 举个例子,如果想要搭建一个聊天机器人,Milvus 一定是其进行数据管理的首选。那么,如何让这个应用程序开发变得易于管理及更好理解,那就需要借助 Towhee(https://towhee.io/)了。…

机器人的触发条件有什么区别,如何巧妙的使用
简介
维格机器人触发条件,分为3个,分别是: 有新表单提交时、有记录满足条件时、有新的记录创建时 。 看似3个,其实是能够满足我们非常多的使用场景。
本篇将先介绍3个条件的触发条件,然后再列举一些复杂的触发条件如何用现有的触发条件来满足
注意: 维格机器人所有的…

Milvus Cloud——Agent 框架工作方式
Agent 框架工作方式 我们以 AutoGPT 为例,看看一个 Agent 框架具体是如何工作的: AutoGPT[2] 使用 GPT-4 来生成任务、确定优先级并执行任务,同时使用插件进行互联网浏览和其他访问。AutoGPT 使用外部记忆来跟踪它正在做什么并提供上下文&am…
Milvus Cloud——Agent 框架工作方式
Agent 框架工作方式 我们以 AutoGPT 为例,看看一个 Agent 框架具体是如何工作的: AutoGPT[2] 使用 GPT-4 来生成任务、确定优先级并执行任务,同时使用插件进行互联网浏览和其他访问。AutoGPT 使用外部记忆来跟踪它正在做什么并提供上下文&am…
Milvus 上新!全新 Range Search 功能,可精准控制搜索结果
Range Search 功能诞生于社区。
某天,一位做系统推荐的用户在社区提出了需求,希望 Milvus 能提供一个新功能,可以返回向量距离在一定范围之内的结果。而这不是个例,开发者在做相似性查询时,经常需要对结果做二次过滤。…

milvus insert api的数据结构源码分析
insert api的数据结构
一个完整的insert例子:
import numpy as np
from pymilvus import (connections,FieldSchema, CollectionSchema, DataType,Collection,
)num_entities, dim 10, 3print("start connecting to Milvus")
connections.connect("default&q…

Milvus Cloud与携程的向量探索大公开
【User Tech】2024 我们来啦! 今年,【User Tech】将更加专注于为社区用户提供技术功能解读、热点答疑,聚焦更丰富、更多样化的行业或使用场景的用户案例。我们期待通过分享更多关于 Milvus Cloud 的实战经验,为大家在 AI、大模型、…

ModaHub魔搭社区:Milvus的工作原理和为什么选择Milvus?
目录
为什么选择 Milvus?
Milvus 的工作原理是什么?
Milvus 由存储层和计算层组成,为了增强弹性和灵活性,Milvus 中的所有组件都是无状态的。系统由四个层级组成:
Milvus 用于什么?
如今,已…
ModaHub魔搭社区:星环科技致力于打造更优越的向量数据库
在数字化时代,数据成为了最重要的资源之一。随着人工智能、大数据等技术的不断发展,向量数据库成为了处理这类数据的关键工具。星环科技作为一家专注于数据存储和管理技术的公司,其重要目标就是将向量数据库打造得更为优越。 在星环科技,有一个专注于向量数据库的团队。这个…
docker安装milvus后,无法打开attu,日志报错
背景,在虚拟机用docker安装milvus后,正常访问attu,过段时间挂机后无法访问
日志报错:
[2024/02/19 06:59:46.761 00:00] [ERROR] [grpcclient/client.go:330] ["ClientBase ReCall grpc second call get error"] [rol…
向量数据库Annoy和Milvus
Annoy 和 Milvus 都是用于向量索引和相似度搜索的开源库,它们可以高效地处理大规模的向量数据。
Annoy(Approximate Nearest Neighbors Oh Yeah):
Annoy 是一种近似最近邻搜索算法,它通过构建一个树状结构来加速最近…
Milvus Cloud——LLM Agent 现阶段出现的问题
LLM Agent 现阶段出现的问题 由于一些 LLM(GPT-4)带来了惊人的自然语言理解和生成能力,并且能处理非常复杂的任务,一度让 LLM Agent 成为满足人们对科幻电影所有憧憬的最终答案。但是在实际使用过程中,大家逐渐发现了通…
Milvus Cloud——LLM Agent 现阶段出现的问题
LLM Agent 现阶段出现的问题 由于一些 LLM(GPT-4)带来了惊人的自然语言理解和生成能力,并且能处理非常复杂的任务,一度让 LLM Agent 成为满足人们对科幻电影所有憧憬的最终答案。但是在实际使用过程中,大家逐渐发现了通…

《向量数据库》——为何向量数据库对大模型LLM很重要?
当您浏览Twitter、LinkedIn或新闻源上的时间轴时,可能会看到一些关于聊天机器人、LLM和GPT的内容。因为每周都有新的LLM发布,很多人都在谈论LLM。
我们目前置身于一场人工智能革命,许多新应用都依赖于向量嵌入。不妨让我们更多地了解向量数据库以及为什么它们对LLM很重要。…
Milvus向量数据库常见用法
创建/断开客户端连接
from pymilvus import connections
# 创建连接
connections.connect(alias"default",userusername,passwordpassword,hostlocalhost,port19530
)# 断开连接
connections.disconnect("default")管理Collection
创建Collection
# 定义…

《向量数据库指南》——文心大模型+Milvus向量数据库搭建AI原生应用
亲爱的科技探险家们和代码魔法师们: 未来的钟声已经敲响,预示着一场极度炫酷的虚拟现实游戏即将展开。从初期简单的智能识别,到设计师级别的图纸设计,生成式AI技术(Generative AI)以其独特理念和创新模式重塑了传统内容生产效率和交互模式,在无数领域展现着非凡的才华。…

Docker Compose安装milvus向量数据库单机版-milvus基本操作
目录 安装Ubuntu 22.04 LTS在power shell启动milvus容器安装docker desktop下载yaml文件启动milvus容器Milvus管理软件Attu python连接milvus配置下载wget示例导入必要的模块和类与Milvus数据库建立连接创建名为"hello_milvus"的Milvus数据表插入数据创建索引基于向量…
《向量数据库指南》——AI原生向量数据库Milvus Cloud 2.3稳定性
在当今的互联网时代,稳定性是所有系统和应用程序的关键要素。无论是大型数据中心还是个人电脑,稳定性都是保证正常运行和用户体验的基础。在这个背景下,我们来谈谈 Milvus,一个开源的向量数据库,它在 2.1.0 版本中引入了内存多副本的概念。
Milvus 是一个开源的向量数据库…
Milvus Cloud ——Agent 的展望
Agent 的展望 目前,LLM Agent 大多是处于实验和概念验证的阶段,持续提升 Agent 的能力才能让它真正从科幻走向现实。当然,我们也可以看到,围绕 LLM Agent 的生态也已经开始逐渐丰富,大部分工作都可以归类到以下三个方面进行探索: Agent模型 AgentBench[4] 指出了不同的 L…
Milvus Cloud ——Agent 的展望
Agent 的展望 目前,LLM Agent 大多是处于实验和概念验证的阶段,持续提升 Agent 的能力才能让它真正从科幻走向现实。当然,我们也可以看到,围绕 LLM Agent 的生态也已经开始逐渐丰富,大部分工作都可以归类到以下三个方面进行探索: Agent模型 AgentBench[4] 指出了不同的 L…

《向量数据库指南》——2023云栖大会现场,向量数据库Milvus Cloud成关注焦点
近期,广受关注的2023 云栖大会正式收官,来自全球各地的开发者集聚一堂,共同探索 AI 时代的更多可能性。
云栖大会是由阿里巴巴集团主办的科技盛宴,是中国最早的开发者创新展示平台。据悉,今年云栖大会的主题为“计算,为了无法计算的价值”,共吸引了全球 44 个国家和地区…

星环科技向量数据库Transwarp Hippo1.1发布:一库搞定向量+全文联合检索,提升大模型准确率
星环科技向量数据库Transwarp Hippo自发布已来,受到了众多用户的欢迎,帮助用户实现向量数据的存储、管理和检索,探索和实践大模型场景。在与用户不断地深入交流以及实践中,Hippo迎来了V1.1版本,一套系统即可支持向量与全文联合检索,提高文本数据的召回精度,从而提升大语…
Milvus实战:构建QA系统及推荐系统
Milvus简介
全民AI的时代已经在趋势之中,各类应用层出不穷,而想要构建一个完善的AI应用/系统,底层存储是不可缺少的一个组件。 与传统数据库或大数据存储不同的是,这种场景下则需要选择向量数据库,是专门用来存储和查…

《向量数据库指南》——向量数据库Elasticsearch -> Milvus 2.x
Elasticsearch -> Milvus 2.x 1. 准备 ES 数据 要迁移 ES 数据,前提假设您已经拥有属于自己的 es Server(自建、ElasticCloud、阿里云 ES 等),向量数据存储在 dense_vector,以及其他字段在 index 中,index mapping 形式如: 2. 编译打包 首先下载迁移项目源码:https…

《向量数据库指南》——用了解向量数据库Milvus Cloud搭建高效推荐系统
了解向量数据库
ANN 搜索是关系型数据库无法提供的功能。关系型数据库只能用于处理具有预定义结构、可直接比较值的表格型数据。因此,关系数据库索引也是基于这一点来比较数据。但是 Embedding 向量无法通过这种方式直接相互比较。因为我们不知道向量中的每个值代表什么意思,…
milvus使用python调用时连接失败 pymilvus.exceptions.MilvusException
报错: File "/root/anaconda3/envs/python3.8/lib/python3.8/site-packages/langchain/vectorstores/milvus.py", line 151, in __init__self.alias self._create_connection_alias(connection_args)File "/root/anaconda3/envs/python3.8/lib/pyth…
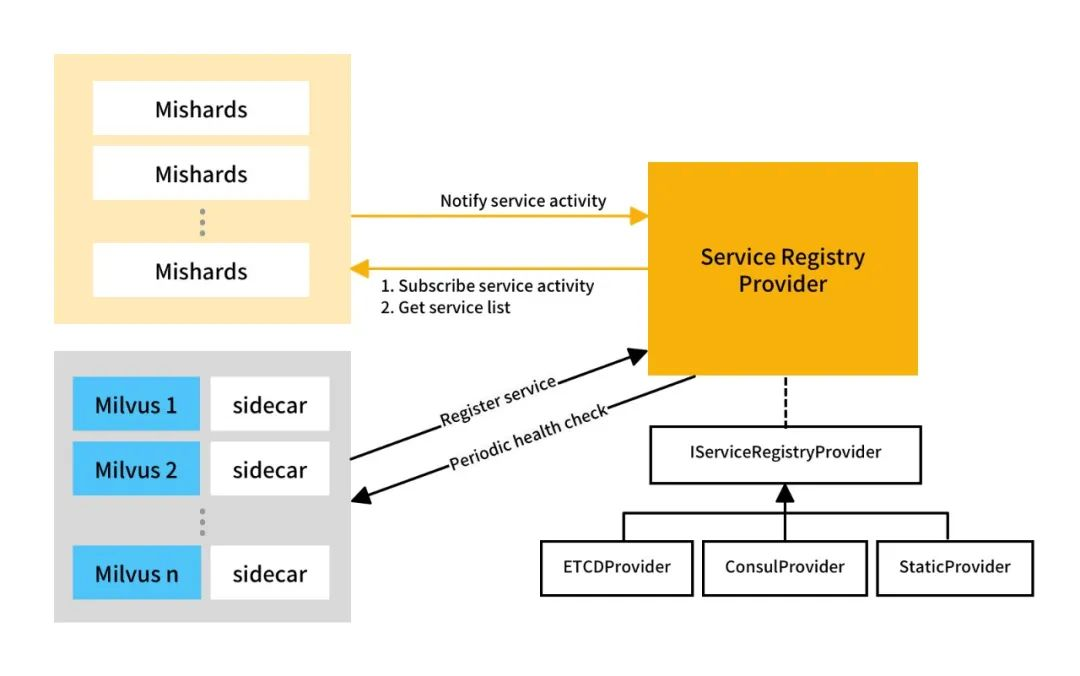
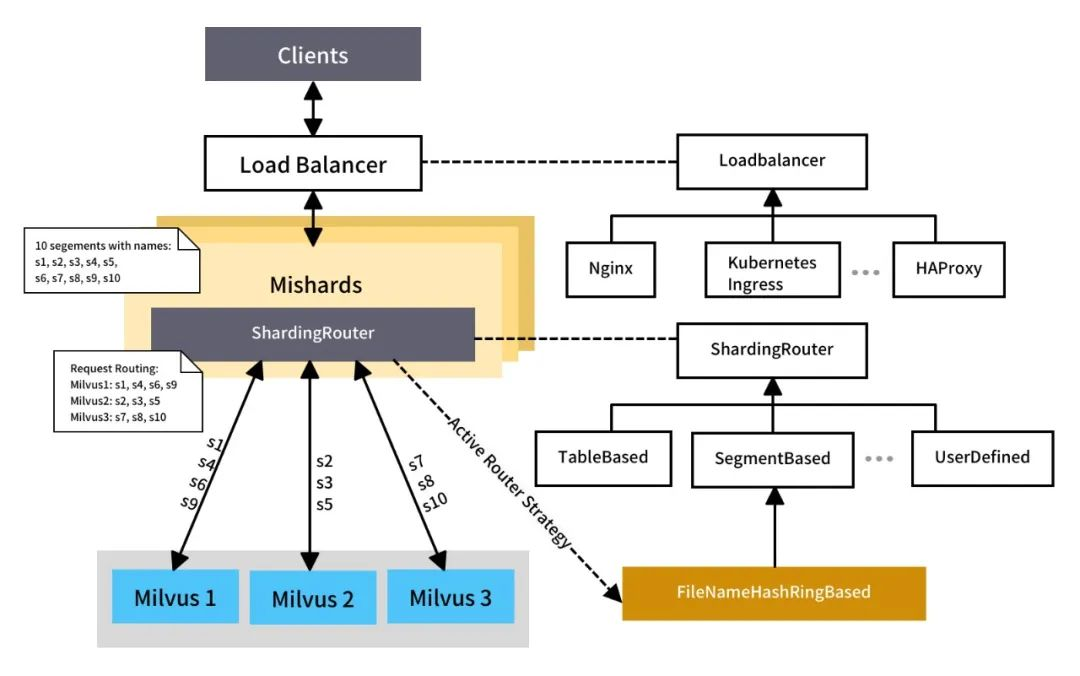
ModaHub魔搭社区:详解向量数据库Milvus的Mishards:集群分片中间件(二)
目录
元数据
服务发现 元数据
元数据记录了底层数据的组织结构信息。在分布式系统中,Milvus 写节点是元数据唯一的生产者,而 Mishards 节点、Milvus 写节点和读节点都是元数据的消费者。目前版本的 Milvus 只支持 MySQL 和 SQLite 作为元数据的存储后…

ModaHub魔搭社区:向量数据库Milvus使用 MySQL 管理元数据教程
目录
使用 MySQL 管理元数据
常见问题
数据管理相关博客 使用 MySQL 管理元数据
Milvus 默认使用 SQLite 作为元数据后台管理服务,SQLite 内嵌于 Milvus 进程中,无需启动额外服务。但是在生产环境中,基于可靠性的考虑,我们强烈…

AI 未来已至,向量数据库站在新的节点上
“AI 的 iPhone 时刻已经到来。”
在刚刚结束的 NVIDIA GTC Keynote 中,这句话被 NVIDIA CEO 黄仁勋反复提及,长达 1 个多小时的分享中,生成式 AI 相关的内容占据了绝大部分比重。他表示,生成式 AI 的火热能力为企业带来了挑战&a…
向量数据库Milvus Cloud 2.3 工具升级: 解锁全新的运维功能
Milvus Cloud 2.3 已经发布,并且带来了一系列令人激动的新功能和升级。在这次升级中,Birdwatcher工具也得到了全面升级,为用户提供了更多强大的功能和更便捷的操作方式。在这篇文章中,我们将深入探讨Birdwatcher工具的升级内容,并带您一览Milvus Cloud 2.3的运维新特性。 …
Milvus踩坑笔记
本文用于记录在学习 Milvus文档时所遇到的一些Bug或报错及解决方法
参考文章:
官方demo:在Dynamic Schema的集合中插入数据
报错1:auto id enabled, id shouldnt in entities[0]
问题描述
此报错出现在Milvus官方在介绍 Dynamic Schema …
LangChain,构建带有Milvus存储的问题分析任务
LangChain简述
LangChain 就是一个 LLM 编程框架,你想开发一个基于 LLM 应用,需要什么组件它都有,直接使用就行;甚至针对常规的应用流程,它利用链(LangChain中Chain的由来)这个概念已经内置标准化方案了。下面我们从新…

如何用个人数据Milvus Cloud知识库构建 RAG 聊天机器人?(上)
生成式人工智能时代,开发者可以借助大语言模型(LLM)开发更智能的应用程序。然而,由于有限的知识,LLM 非常容易出现幻觉。检索增强生成(RAG)https://zilliz.com/use-cases/llm-retrieval-augmented-generation 通过为 LLM 补充外部知识,有效地解决了这一问题。 在 Chat …
《向量数据库指南》——向量数据库是小题大作的方案?
假设大语言模型需要 10 秒钟才能生成一条结果,即需要存储的单条新记忆。那么我们获得 10 万条记忆的时间周期将为:100000 x 10 秒 = 1000000 秒——约等于 11.57 天。而即使我们用最简单的暴力算法(Numpy 的点查询),整个过程也只需要几秒钟时间,完全不值得进行优化!也就…

向量数据库Weaviate Cloud 和 Milvus Cloud:性能大比拼
最近,随着检索增强生成系统(RAG)的持续火爆,开发者对于“如何选择一个向量数据库”的疑惑也越来越多。过去几周,我们从性能和特性能力两个方面对 Weaviate Cloud 和 MilvusCloud 进行了详细的对比。在对比过程中,我们使用了开源的性能基准测试套件 VectorDBBench,围绕诸…
Milvus向量数据库 --- 01 基本词汇概念
Schema:Milvus向量数据的库的Schema是指向量数据的模式定义,包括向量的维度、向量数据类型、索引类型等。Schema是Milvus中非常重要的概念,它定义了向量数据的基本属性和特征。 Segment:Milvus向量数据的库中,Segment…
Milvus 入门教程
文章目录 下载docker-compose配置文件安装 docker安装docker-compose直接下载release版本手动安装使用pip 命令自动安装 通过 docker-compose 启动容器连接 Milvus停止 milvus删除milvus的数据 下载docker-compose配置文件
先安装wget命令
yum install wget下载配置文件&…

《这里数据库指南》——如何用 LlamaIndex和Milvus Cloud 搭建聊天机器人的总结?
LlamaIndex 是领先的开源数据检索框架,能够在各种应用中发挥优势,其中一个典型的应用就是在企业内部搭建聊天机器人。 对于企业而言,随着文档数量不断增多,文档管理会变得愈发困难。因此,许多企业会基于内部知识库搭建…

用向量数据库Milvus Cloud搭建GPT大模型+私有知识库的定制AI助手——PPT大纲助手
随着人工智能技术的不断发展,AI助手在各行各业中扮演着越来越重要的角色。在商业领域,PPT演示是一种常见的沟通方式,而定制化的PPT大纲助手能够极大地提高PPT制作效率和质量。本文将介绍如何利用向量数据库Milvus Cloud搭建GPT大模型和私有知识库,构建一款高效的PPT大纲助手…
Milvus 向量数据库:如何基于docker-compose在本地快速搭建测试环境
文章目录 1. 安装 milvus1.1. milvus v2.3.12版本信息1.2. 安装milvus步骤1.3. 安装管理工具Attu1.4. 将Attu由docker-compose启动参考Milvus 向量数据库专为向量查询与检索设计,能够为万亿级向量数据建立索引,详见介绍请参见: milvus: 专为向量查询与检索设计的向量数据库 …

《向量数据库指南》——Milvus Cloud向量数据库的优势
大禹智库:
随着大模型的爆火,向量数据库也越发成为开发者关注的焦点。为了方便大家更好地了解向量数据库,我们特地推出了《Hello, VectorDB》系列,本文将从宏观角度、向量数据库与其他算法库的区别、技术难点及如何选择向量数据库等方面,带大家认识真正的向量数据库。 在…

《向量数据库指南》——完善产品拼图,GBASE南大通用发布向量数据库
在AIGC所引发的新一轮AI浪潮中,向量数据库成为资本的宠儿,引发了广泛关注,越来越多的数据库厂商布局向量数据库。 日前,在刚刚结束的第二十五届中国国际软件博览会中国数据库产业峰会上,南大通用发布了GBase向量数据库GBase Cloud Vector DB,也带来了他们对市场的观察、思…
Annoy vs Milvus:哪个向量数据库更适合您的AI应用?知其然知其所以然
1. Annoy vs Milvus简介
Annoy 和 Milvus 都是用于向量索引和相似度搜索的开源库,它们可以高效地处理大规模的向量数据。
Annoy(Approximate Nearest Neighbors Oh Yeah):
Annoy 是一种近似最近邻搜索算法,它通过构…
7个向量数据库对比:Milvus、Pinecone、Vespa、Weaviate、Vald、GSI 和 Qdrant
本文简要总结了当今市场上正在积极开发的7个向量数据库,Milvus、Pinecone、Vespa、Weaviate、Vald、GSI 和 Qdrant 的详细比较。 我们已经接近在搜索引擎体验的基础层面上涉及机器学习:在多维多模态空间中编码对象。这与传统的关键字查找不同(…
ModaHub魔搭社区:VectorDBBench的工作原理和目标
目录 VectorDBBench工作原理
VectorDBBench目标 VectorDBBench工作原理
VectorDBBench不仅仅是主流矢量数据库和云服务的基准测试结果,它还是您进行最终性能和成本有效性比较的首选工具。VectorDBBench的设计考虑到了易用性,旨在帮助用户,甚…

ModaHub魔搭社区:向量数据库Milvus产品问题(一)
目录
产品问题
Milvus 会收费吗?
Milvus 支持非 x86 平台吗?
Milvus 支持对向量的插入、删除、更改和查询操作吗?
Milvus 可以处理百亿或千亿级数据吗?
Milvus 数据存储在哪里?
为什么我在 SQLite / MySQL 找不…
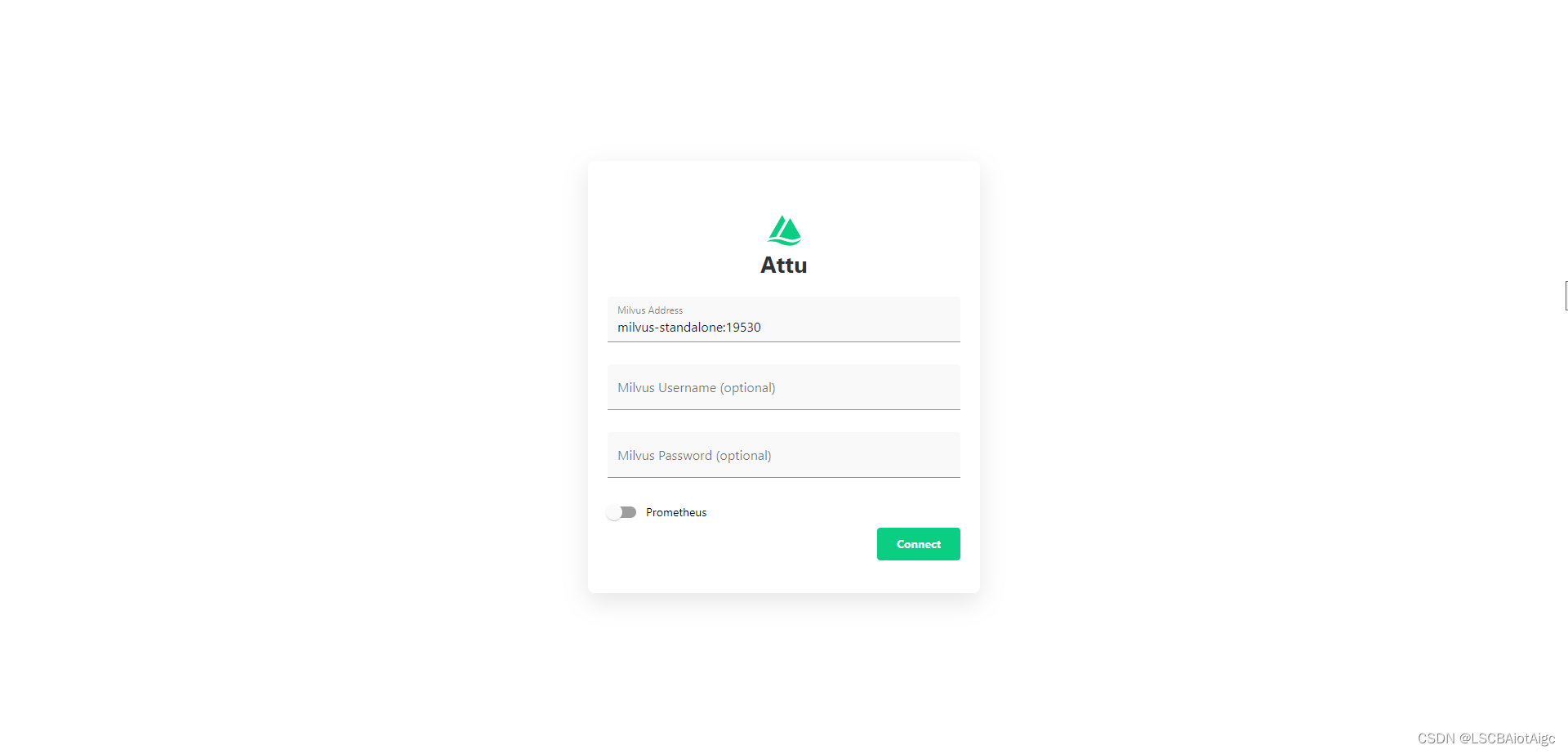
LangChain结合milvus向量数据库以及GPT3.5结合做知识库问答之一 --->milvus的docker compose安装
https://github.com/milvus-io/milvus/releaseshttps://github.com/milvus-io/milvus/releases
以下步骤均在Linux环境中进行:
将milvus-standalone-docker-compose.yml下载到本地。
1、新建一个目录milvus
2、将milvus-standalone-docker-compose.yml放到milvu…

向量数据库风起时,闭源「墨奇AI数据库」想成为第三种存在
AI大模型时代下,图片、视频、自然语言等多模态的非结构化数据量陡增,而大模型支持的token数有限,虽然可以在RLHF的配合下具备一定程度的“短期记忆”,但正是因为“长期记忆”的缺失,导致大模型经常会出现“一本正经地胡说八道”的情况。 区别于用来处理结构化数据的传统数…

Milvus Cloud扩展变更:为向量数据库注入前沿增强功能
在向量数据库的不断变化中,Milvus Cloud已成为一个改变游戏规则的先锋,革新了我们存储、搜索和分析复杂向量数据的方式。通过最新版本的Milvus Cloud2.3.0,引入了一系列重要的增强和修改,为更强大、更高效的向量数据库解决方案铺平了道路。在本文中,我们将深入探讨Milvus …

《向量数据库指南》——TruLens + Milvus Cloud构建RAG深入了解性能
深入了解性能 索引类型 本例中,索引类型对查询速度、token 用量或评估没有明显影响。这可能是因为数据量较小的关系。索引类型对较大语料库可能更重要。 Embedding 模型 text-embedding-ada-002 在准确性(0.72,平均 0.60)和答案相关度(0.82,平均0.62)上优于 MiniLM Embeddin…
milvus数据库-连接
Milvus 支持 19530 和 9091 两个端口:
端口 19530 用于 gRPC 和 RESTful API。 这是您使用不同 Milvus SDK 或 HTTP 客户端连接到 Milvus 服务器时的默认端口。 端口 9091 用于 Kubernetes 内的指标收集、pprof 分析和运行状况探测。 它用作管理端口。
1.连接到数…

《向量数据库指南》——TruLens + Milvus Cloud 构建RAG案例
具体案例 如前所述,RAG 配置选择可能对消除幻觉产生重大影响。下文中将基于城市百科文章构建问答 RAG 应用并展示不同的配置选择是如何影响应用性能的。在搭建过程中,我们使用 LlamaIndex 作为该应用的框架。大家可以在 Google Colab( https://colab.research.google.com/git…
《向量数据库指南》——Milvus Cloud构建 RAG
在构建高效的 RAG 式 LLM 应用程序时,我们有许多可以优化的配置,不同配置的选择极大影响了检索质量。可以选择的配置包括: 向量数据库的选择 数据选择 Embedding 模型 索引类型 找到高质量、能精准符合需求的数据非常关键。如果数据不够准确,检索可能返回无关的结果。选择好…
Milvus Cloud——LangChain 分块简介
LangChain 分块简介 LangChain 是一个 LLM 协调框架,内置了一些用于分块以及加载文档的工具。本次分块教程主要围绕设置分块参数,并最小限度地使用 LLM。简而言之,通过编写一个函数并设置其参数来加载文档并对文档进行分块,该函数打印结果为分块后的文本块。在下述实验中,…
Milvus Cloud——LangChain 分块简介
LangChain 分块简介 LangChain 是一个 LLM 协调框架,内置了一些用于分块以及加载文档的工具。本次分块教程主要围绕设置分块参数,并最小限度地使用 LLM。简而言之,通过编写一个函数并设置其参数来加载文档并对文档进行分块,该函数打印结果为分块后的文本块。在下述实验中,…

《向量数据库指南》——Milvus Cloud和Elastic Cloud 特性对比
随着以 Milvus 为代表的向量数据库在 AI 产业界越来越受欢迎,诸如 Elasticsearch 之类的传统数据库和检索系统也开始行动起来,纷纷在快速集成专门的向量检索插件方面展开角逐。 例如,在提供类似插件的传统数据库中,Elasticsearch 8.0 首屈一指,推出了包括向量插入和最相似…
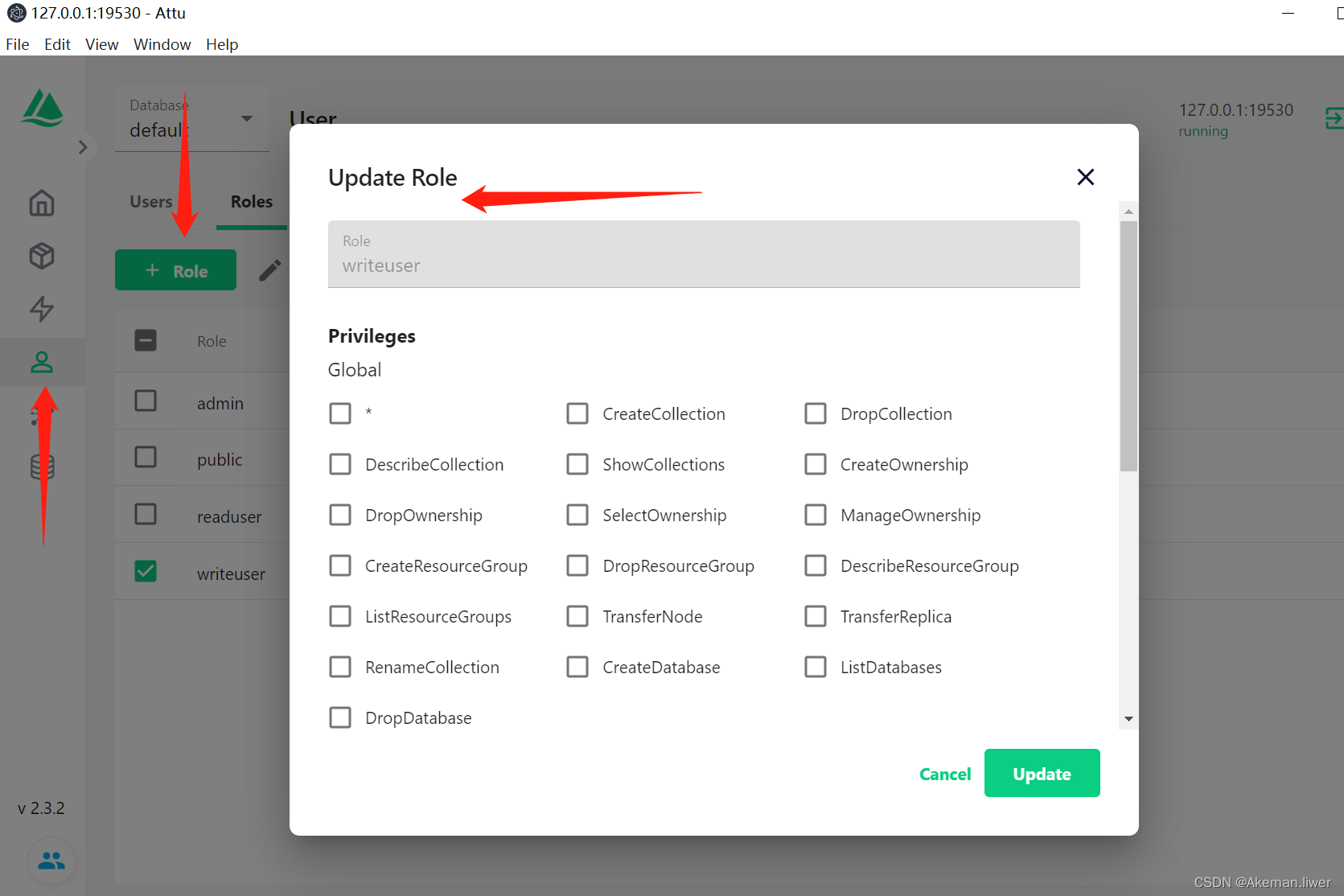
Milvus入门手册1.0
一、window环境搭建(单机)
1、docker安装
略
2、milvus安装
参考文档:https://milvus.io/docs/install_standalone-docker.md tips:
(1)compose.yaml下载比较慢,可以在网络上找一份。
(2&…

ModaHub魔搭社区:星环科技向量数据库Hippo社区版来啦
大语言模型正在与企业应用迅速结合,并深刻改变企业的各个产业环节。而大模型训练所使用的数据包含了如文档、图片、音视频等各种类型的非结构化数据,传统关系型数据库能力有限。通过将这些非结构化数据转换为多维向量,可以结构化地在向量数据库中进行管理,实现高效的数据存…

强大的向量数据库:Milvus
在推荐系统中,向量的最邻近检索是极为关键的一步,特别是在召回流程中。一般常用的如Annoy、faiss都可以满足大部分的需求,今天再来介绍另外一个:Milvus
Milvus
Milvus不同于Annoy、faiss这类型的向量检索工具,它更是…

《向量数据库指南》——Milvus Cloud当初为什么选择向量数据库这个赛道呢?
我们公司专注于向量数据库大约可以追溯到 2018 年左右。当时,向量数据库的概念并不广泛。我们的 CEO 力排众议,认为这个领域有巨大潜力,因为这与我们的愿景高度契合。我们的公司定位是构建一个能够在云上处理非结构化数据的基础设施产品。经过…
《向量数据库指南》——Milvus Cloud当初为什么选择向量数据库这个赛道呢?
我们公司专注于向量数据库大约可以追溯到 2018 年左右。当时,向量数据库的概念并不广泛。我们的 CEO 力排众议,认为这个领域有巨大潜力,因为这与我们的愿景高度契合。我们的公司定位是构建一个能够在云上处理非结构化数据的基础设施产品。经过…

Milvus Cloud向量数据库或率先在垂直领域体现价值
从市场维度上看,尽管大模型带火了向量数据库,多家初创公司受到资本市场青睐,但是其商业化落地和规模化应用的前景仍不明朗:一方面,技术迭代慢,没有新的突破。向量数据库核心技术包括索引、相似度计算、Embedding等,这些技术早已出现,时至今日并没有实现大的创新突破;另…
Milvus Cloud向量数据库或率先在垂直领域体现价值
从市场维度上看,尽管大模型带火了向量数据库,多家初创公司受到资本市场青睐,但是其商业化落地和规模化应用的前景仍不明朗:一方面,技术迭代慢,没有新的突破。向量数据库核心技术包括索引、相似度计算、Embedding等,这些技术早已出现,时至今日并没有实现大的创新突破;另…
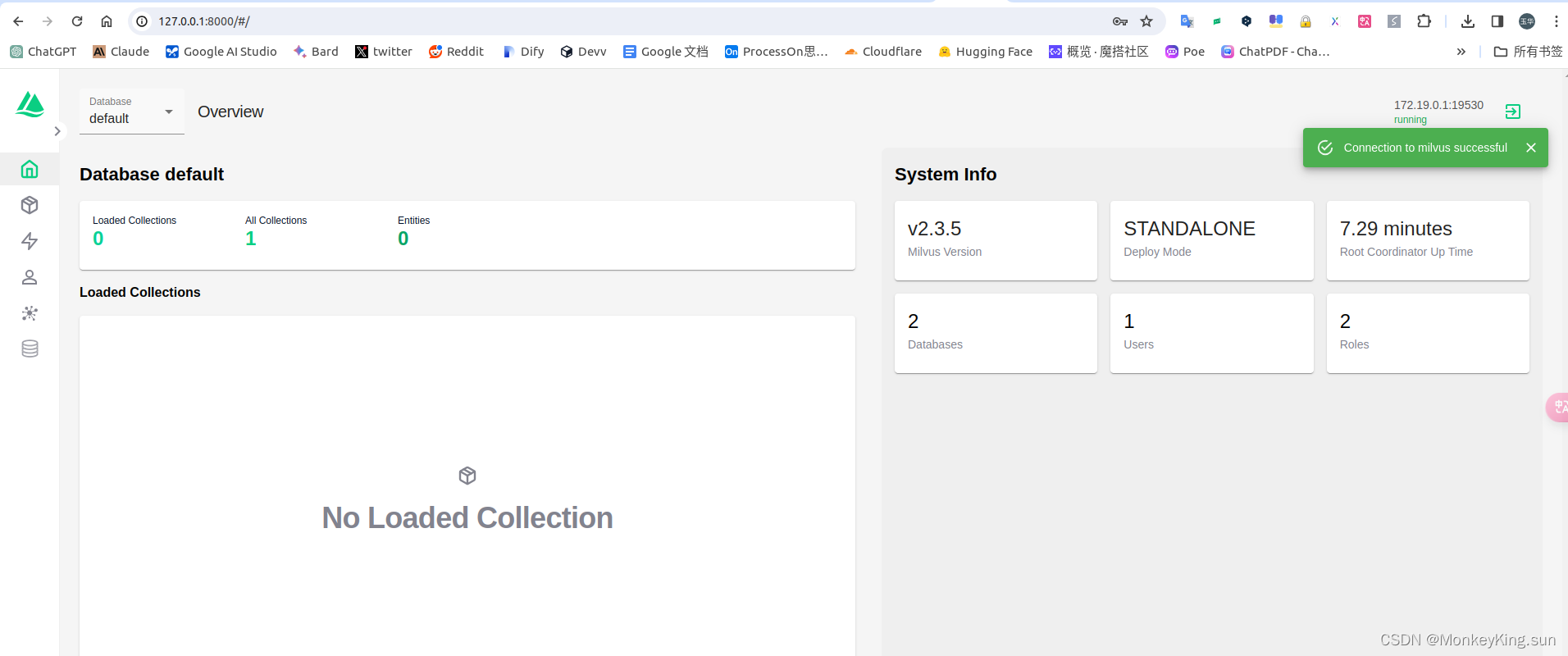
《向量数据库指南》——提高向量数据库Milvus Cloud 2.3的运行效率
简介:向量数据库彻底改变了我们处理复杂数据结构的方式: 向量数据库彻底改变了我们处理复杂数据结构的方式,为高维矢量提供了高效的存储和检索。作为向量数据库专家和《向量数据库指南》的作者,我很高兴能与大家分享向量数据库运行效率方面的最新进展。在本文中,我们将探讨…

向量数据库Milvus Cloud核心组件再升级,主打就是一个低延迟、高准确度
支持 ScaNN 索引
Faiss 实现的 ScaNN,又名 FastScan,使用更小的 PQ 编码和相应的指令集可以更为友好地访问 CPU 寄存器,从而使其拥有优秀的索引性能。该索引在 Cohere 数据集,Recall 约 95% 的时候,Milvus 使用 Knowhere 2.x 版本端到端的 QPS 是 IVF_FLAT 的 7 倍,HN…
milvus的compaction机制
compaction机制 compaction用来合并对象存储的小文件,将小的segment合并为大的segment。 Compaction 有一个配置项来控制是否启用自动压缩。此配置是全局的,会影响系统中的所有集合。 dataCoord.enableCompaction true dataCoord.compaction.enableAuto…

milvus search api的数据结构
search api的数据结构
此api的功能是向量相似度搜索(vector similarity search)
一个完整的search例子:
服务端collection是一个hnsw类型的索引。
import random
from pymilvus import (connections,Collection,
)dim 128if __name__ __main__:connections.connect(alias…
milvus数据管理-删除数据
Milvus 支持通过主键或复杂布尔表达式删除实体。 注意: 如果一致性级别低于Strong,则删除的实体仍然可以在删除后立即检索。 超出Time Travel预设时间范围的删除的实体将无法再次检索。 频繁的删除操作将影响系统性能。 在通过 comlpex 布尔表达式删除实…

ModaHub魔搭社区:向量数据库Milvus性能调优教程(一)
目录
性能调优
插入性能调优
查询性能调优
硬件环境
系统参数 性能调优
插入性能调优
“数据插入”到“数据写入磁盘”的基本流程请参考 存储操作。
如果数据量小于单次插入上限(256 MB),批量插入比单条插入要高效得多。
系统配置中…
《向量数据库指南》——向量数据库一些技术难点
一些技术难点 在文章的前半部分,我们列举了一些向量数据库应该具备的特性,然后比较了以 Milvus 为代表的向量数据库和 ANN 算法库、向量检索插件的不同之处。接下来,我们来聊聊构建向量数据库过程中会遇到的一些技术难点。 就好像一架飞机一样,内部每个零部件和系统相互连通…

Milvus Cloud——什么是 Agent?
什么是 Agent? 根据 OpenAI 科学家 Lilian Weng 的一张 Agent 示意图 [1] 我们可以了解 Agent 由一些组件来组成。 规划模块 子目标分解:Agent 将目标分为更小的、易于管理的子目标,从而更高效地处理复杂的任务。 反省和调整:Agent 可以对过去的行为进行自我批评和自我反思…
向量数据库 Milvus:实现高效向量搜索的技术解析
引言 随着人工智能、机器学习和深度学习技术的不断发展,越来越多的应用开始使用向量表示数据。向量数据具有高维、稀疏和相似性等特点,传统的关系型数据库和键值存储在处理这类数据时面临许多挑战。为了满足大规模、高并发的向量搜索需求,出现…
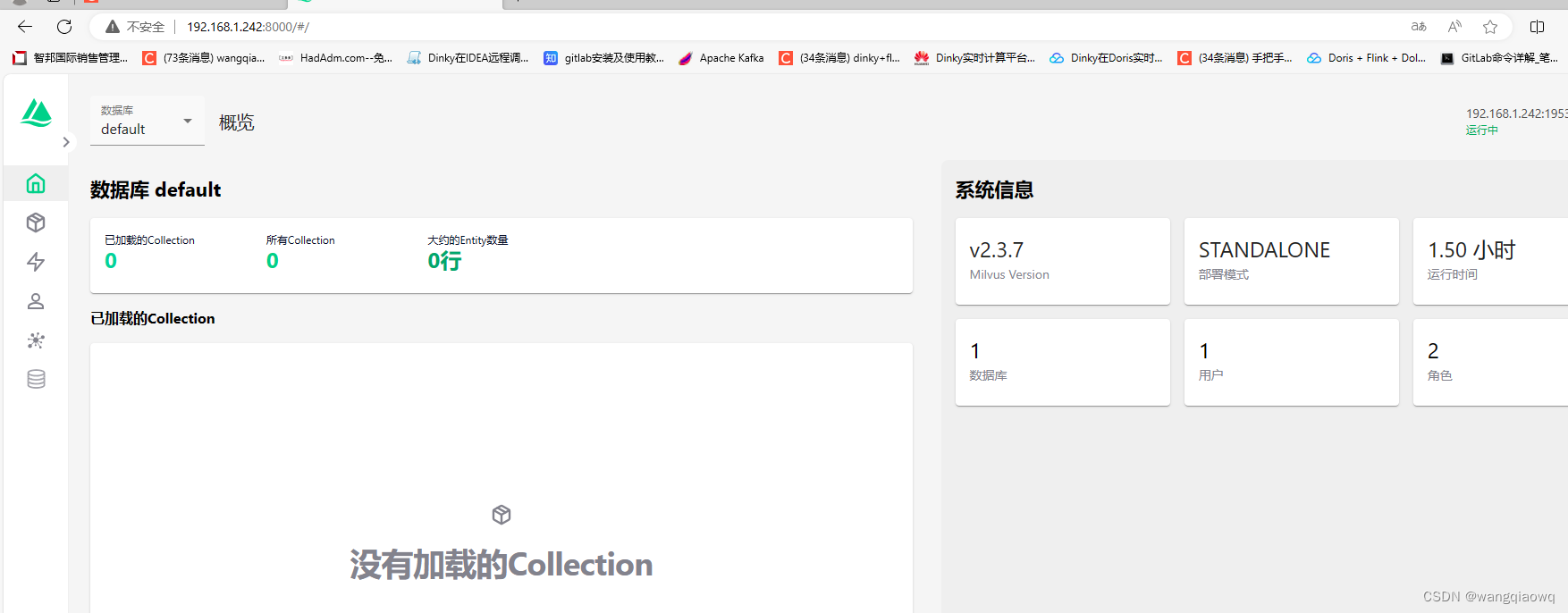
安装向量数据库milvus可视化工具attu
使用docker安装的命令和简单就一个命令:
docker run -p 8000:3000 -e MILVUS_URL{milvus server IP}:19530 zilliz/attu:v2.3.5sunyuhuasunyuhua-HKF-WXX:~/dockercom/milvus$ docker run -p 8000:3000 -e MILVUS_URL127.0.0.1:19530 zilliz/attu:latest
yarn run…
Milvus向量库安装部署
GitHub - milvus-io/milvus-sdk-java: Java SDK for Milvus.
1、安装Standstone 版本
参考:Linux之milvus向量数据库安装_milvus安装-CSDN博客
参考:Install Milvus Standalone with Docker Milvus documentation
一、安装步骤
1、安装docker docke…
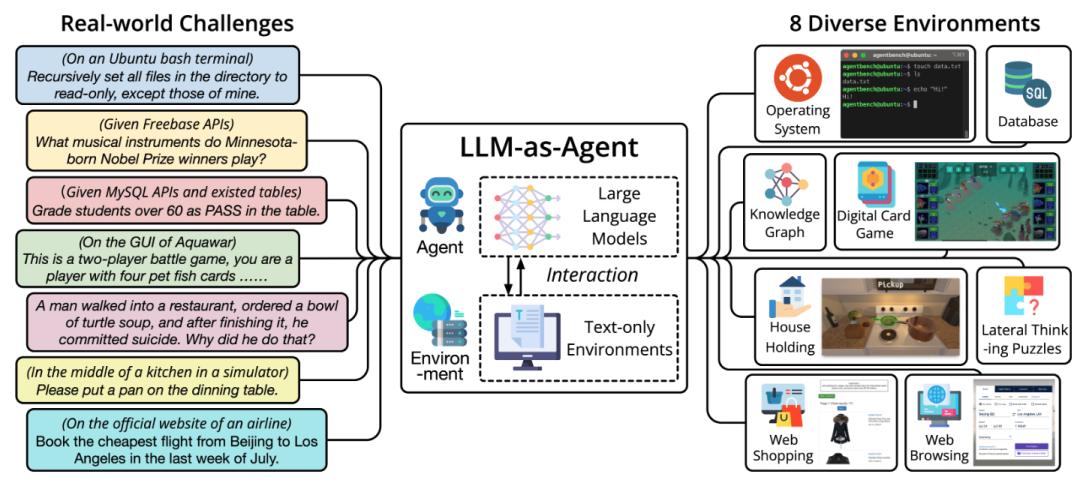
清华团队领衔打造,首个AI agent系统性基准测试网站问世AgentBench.com.cn
AI 智能体,或自主智能代理,不仅是诸如贾维斯等科幻电影中的人类超级助手,也一直是现实世界中 AI 领域的研究热点。尤其是以 GPT-4 为代表的 AI 大模型的出现,将 AI 智能体的概念推向了科技的最前沿。
在此前爆火的斯坦福“虚拟小镇”中,25 个 AI 智能体在虚拟小镇自由生长…

《向量数据库指南》——用 Milvus Cloud和 NVIDIA Merlin 搭建高效推荐系统结果
结果
以下展示基于 CPU 和 GPU 的 3 组性能测试结果。该测试使用了 Milvus 的 HNSW(仅 CPU)和IVF_PQ(CPU 和 GPU)索引类型。 商品向量间相似度搜索 对于给定的参数组合,将 50% 的商品向量作为查询向量,并从剩余的向量中查询出 top-100 个相似向量。我们发现,在测试的参…

ModaHub魔搭社区:向量数据库Milvus部署运维问题教程(一)
目录
部署运维问题
如果在安装 Milvus 时,从 Docker Hub 拉取镜像总是失败怎么办?
Milvus 只能使用 Docker 部署吗?
为什么 Milvus 返回 config check error 的错误?
为什么在导入数据时 Milvus 显示 no space left on devic…
milvus数据库索引管理
一、建立向量索引
默认情况下,Milvus不会对小于1,024行的段进行索引。 1.准备索引参数
index_params {"metric_type":"L2","index_type":"IVF_FLAT","params":{"nlist":1024}
}
#"nlist"…
Milvus数据实体的插入、修改、删除
本节介绍如何通过客户端向 Milvus 中插入数据。您还可以使用 MilvusDM 将数据迁移到 Milvus,MilvusDM 是一款专门用于使用 Milvus 导入和导出数据的开源工具。 Milvus 2.1 支持标量字段上的 VARCHAR 数据类型。为VARCHAR类型标量字段构建索引时,默认…

pymilvus创建向量索引
索引简介
索引的作用是加速大型数据集上的查询。
目前,向量字段仅支持一种索引类型,即只能创建一个索引。
milvus支持的向量索引类型大部分使用近似最近邻搜索算法(ANNS,approximate nearest neighbors search) 。ANNS 的核心思想不再局限于返回最准确…

《低代码指南》——国内首个向量数据库标准亮相,腾讯云联合50家企业共同编制
11月15日,在腾讯云向量数据库技术及产业峰会上,腾讯云全面升级向量数据库多项核心性能,最高支持千亿级向量规模和500万QPS峰值能力,同时和信通院一起联合50多家企业共同发布了国内首个向量数据库标准,推进向量数据库及大模型相关产业走向大规模应用。 腾讯集团高级执行副总…

AI Infra工具关键能力解析:数据准备、模型训练、模型部署与整合
在预训练大模型时代,我们可以从应用落地过程里提炼出标准化的工作流,AI Infra的投资机会得以演绎。传统ML时代AI模型通用性较低,项目落地停留在“手工作坊”阶段,流程难以统一规范。而大规模预训练模型统一了“从0到1”的技术路径,具备解决问题的泛化能力,能够赋能“从1到…

Milvus 向量数据库实践 - 1
假定你已经安装了docker、docker-compose 环境 参考的文档如下: Milvus技术探究 - 知乎 MilvusClient() - Pymilvus v2.3.x for Milvus 一文带你入门向量数据库milvus 一、在docker上安装单机模式milvus数据库 1、 进入milvus官网: Install Milvus Stand…
《向量数据库指南》——哪些需求推动了如Milvus Cloud等的向量数据库的更新和迭代?
这个问题需要深入讨论大模型与向量数据库之间的关系。从去年 ChatGPT 推出时这个问题就开始引发我们的思考。在当时,我们敏锐地意识到这将是一个机遇。然而,在国内,这个概念的认知需要更长的时间。我个人在去年四五月份的美国之行中注意到,数据库在美国已经是一个非常热门的…
《向量数据库指南》——哪些需求推动了如Milvus Cloud等的向量数据库的更新和迭代?
这个问题需要深入讨论大模型与向量数据库之间的关系。从去年 ChatGPT 推出时这个问题就开始引发我们的思考。在当时,我们敏锐地意识到这将是一个机遇。然而,在国内,这个概念的认知需要更长的时间。我个人在去年四五月份的美国之行中注意到,数据库在美国已经是一个非常热门的…
milvus数据库分区管理
一、创建分区
在创建集合时,会默认创建分区_default。 自己手动创建如下:
from pymilvus import Collection
collection Collection("book") # Get an existing collection.
collection.create_partition("novel")二、检测分…
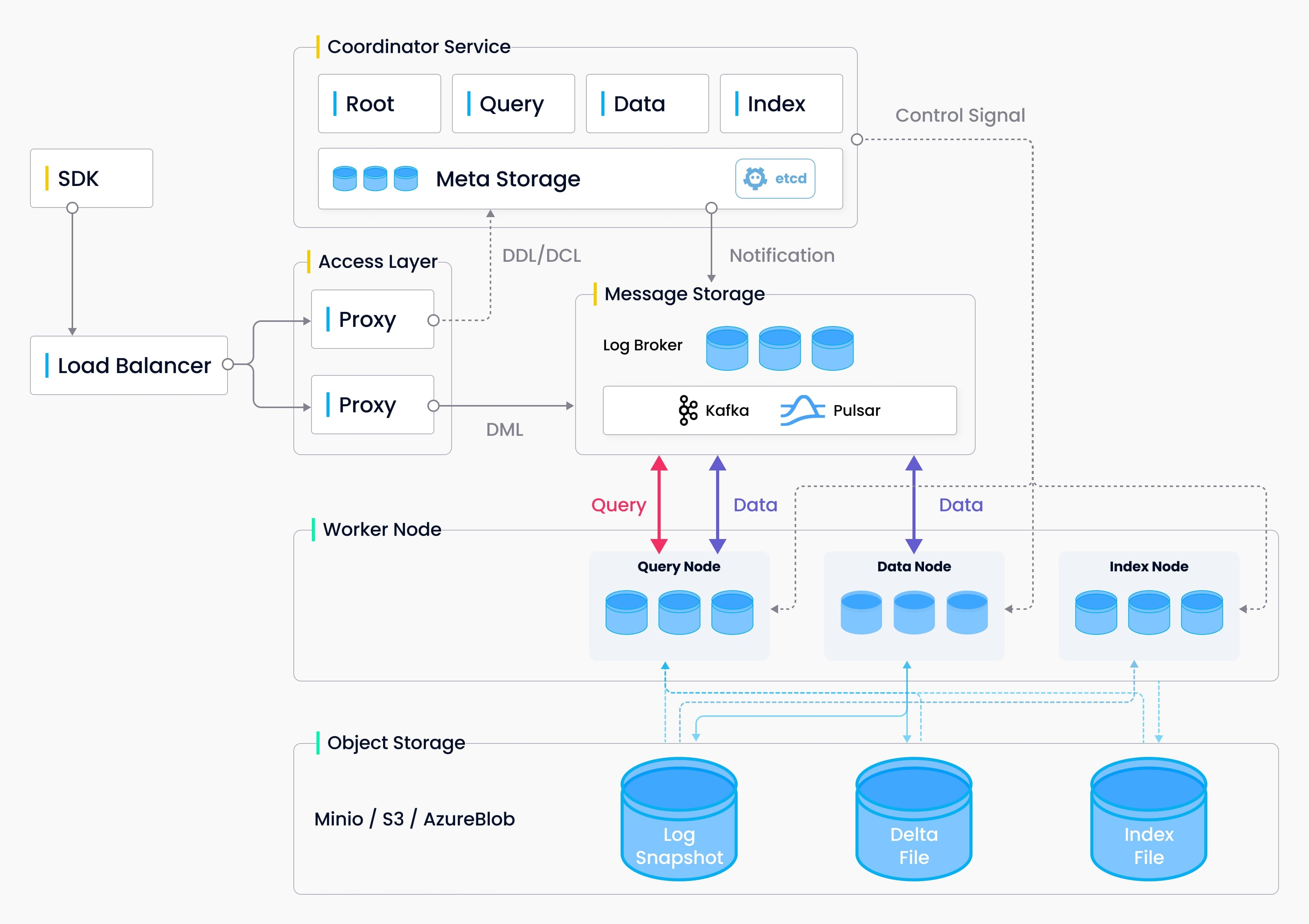
AI实践与学习1_Milvus向量数据库实践与原理分析
前言
随着NLP预训练模型(大模型)以及多模态研究领域的发展,向量数据库被使用的越来越多。
在XOP亿级题库业务背景下,对于试题召回搜索单单靠着ES集群已经出现性能瓶颈,因此需要预研其他技术方案提高试题搜索召回率。…
柏睿向量数据库Rapids VectorDB赋能企业级大模型构建及智能应用
ChatGPT的问世,在为沉寂已久的人工智能重新注入活力的同时,也把长期默默无闻的向量数据库推上舞台。今年4月以来,全球已有4家知名向量数据库公司先后获得融资,更加印证了向量数据库在AI大模型时代的价值。
什么是向量数据库?
在认识向量数据库前,先来了解一下最常见的关…

向量数据库 Milvus Cloud Partition Key:租户数量多,单个租户数据少的三种解决方案
三种解决方案 这个问题提出的时候,Milvus 的最新版本是 2.2.8,我们做个角色互换,在当时站在这个用户的角度,留在我们面前的选择有这么几个: 为每个租户创建一个 collection 为每个租户创建一个 partition 创建一个租户名称的标量字段 接下来,我们依次分析下这三种方案的可…
LLM之高性能向量检索库
LLM向量数据库 高性能向量检索库milvus简介安装调用 faiss简介安装调用 高性能向量检索库
milvus
简介 Milvus 是一个开源的向量数据库引擎,旨在提供高效的向量存储、检索和分析能力。它被设计用于处理大规模的高维向量数据,常用于机器学习、计算机视觉…

Milvus向量数据库检索
官方文档:https://milvus.io/docs/search.md 本节介绍如何使用 Milvus 搜索实体。 Milvus 中的向量相似度搜索会计算查询向量与具有指定相似度度量的集合中的向量之间的距离,并返回最相似的结果。您可以通过指定过滤标量字段或主键字段的布尔表达…
开源模型应用落地-业务优化篇(八)
一、前言 在之前的学习中,我相信您已经学会了一些优化技巧,比如分布式锁、线程池优化、请求排队、服务实例扩容和消息解耦等等。现在,我要给您介绍最后一篇业务优化的内容了。这个优化方法是通过定时统计问题的请求频率,然后将一些…
《向量数据库指南》——AI原生Milvus Cloud 中NATS 配置项详解
当前配置项支持下述的定制化配置能力: natsmq:server: # server side configuration for natsmq.port: 4222 # 4222 by default, Port for nats server listening.storeDir: /var/lib/milvus/nats # /var/lib/milvus/nats by default, directory to use for JetStream storage…
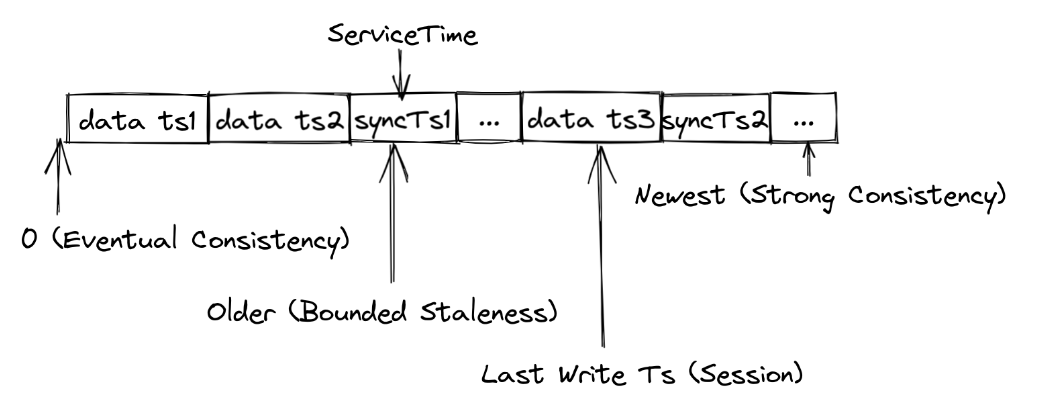
Milvus数据一致性介绍及选择方法
1、Milvus 时钟机制
Milvus 通过时间戳水印来保障读链路的一致性,如下图所示,在往消息队列插入数据时, Milvus 不光会为这些插入记录打上时间戳,还会不间断地插入同步时间戳,以图中同步时间戳 syncTs1 为例࿰…

重磅版本发布|三大关键特性带你认识 Milvus 2.2.9 :JSON、PartitionKey、Dynamic Schema
亮点颇多、精彩程度堪比大版本的 Milvus 2.2.9 来啦!
随着 LLM 的持续火爆,众多应用开发者将目光投向了向量数据库领域,而作为开源向量数据库的领先者,Milvus 也充分吸收了大量来自社区、用户、AI 从业者的建议,把重心…
milvus数据库-查询
与向量相似性搜索不同,向量查询通过基于布尔表达式的标量过滤来检索向量。Milvus支持许多标量字段中的数据类型和各种布尔表达式。布尔表达式过滤标量字段或主键字段,并检索与过滤器匹配的所有结果。
一、单次查询 1.加载集合 2.执行查询
# 使用集合对…
milvus数据管理-upsert实体
upsert是update和insert的缩写词。在数据库中指更新插入,若记录存在,则更新;若不存在,就插入。
一、准备数据
数据的类型必须和集合的模式匹配 对于标量字段,可以留空,但是主键不能为空。
import random…
Milvus+ATTU环境搭建
1.使用Docker Compose安装Milvus Standalone
下载安装单机版milvus向量数据库 https://milvus.io/docs/install_standalone-docker.md
wget https://github.com/milvus-io/milvus/releases/download/v2.2.12/milvus-standalone-docker-compose.yml -O docker-compose.yml
sud…
LLM--使用Milvus向量数据库必须知道的基本概念
Milvus 是一款专为大规模向量相似度搜索而设计的开源向量数据库。它旨在高效、快速地处理高维向量数据,并支持实时、近似最近邻(Approximate Nearest Neighbor, ANN)检索,适用于各种涉及向量搜索的应用场景,如图像识别、语音识别、推荐系统、自然语言处理(NLP)等。
mil…
Milvus以及Web UI 安装
向量数据库懂的都懂 版本数据
[rootiZ7xv7q4im4c48qen2do2bZ project]# cat /etc/redhat-release
CentOS Stream release 9
[rootiZ7xv7q4im4c48qen2do2bZ project]# docker version
Client: Docker Engine - CommunityVersion: 24.0.5API version: 1.43Go v…

《向量数据库》——向量数据库MIlvus Cloud携手发起 AGI 黑客松,解锁行业更多可能
携手发起 AGI 黑客松,解锁行业更多可能 不止如此,双方在深度合作的基础上,还联合极客公园 Founder Park、智谱 AI 等,共同发起 AGI Playground Hackathon,旨在重新思考 AI Native 时代下的应用和服务,解决共同的行业发展问题。届时,Dify 将为参赛者提供接入了智谱 AI 模…
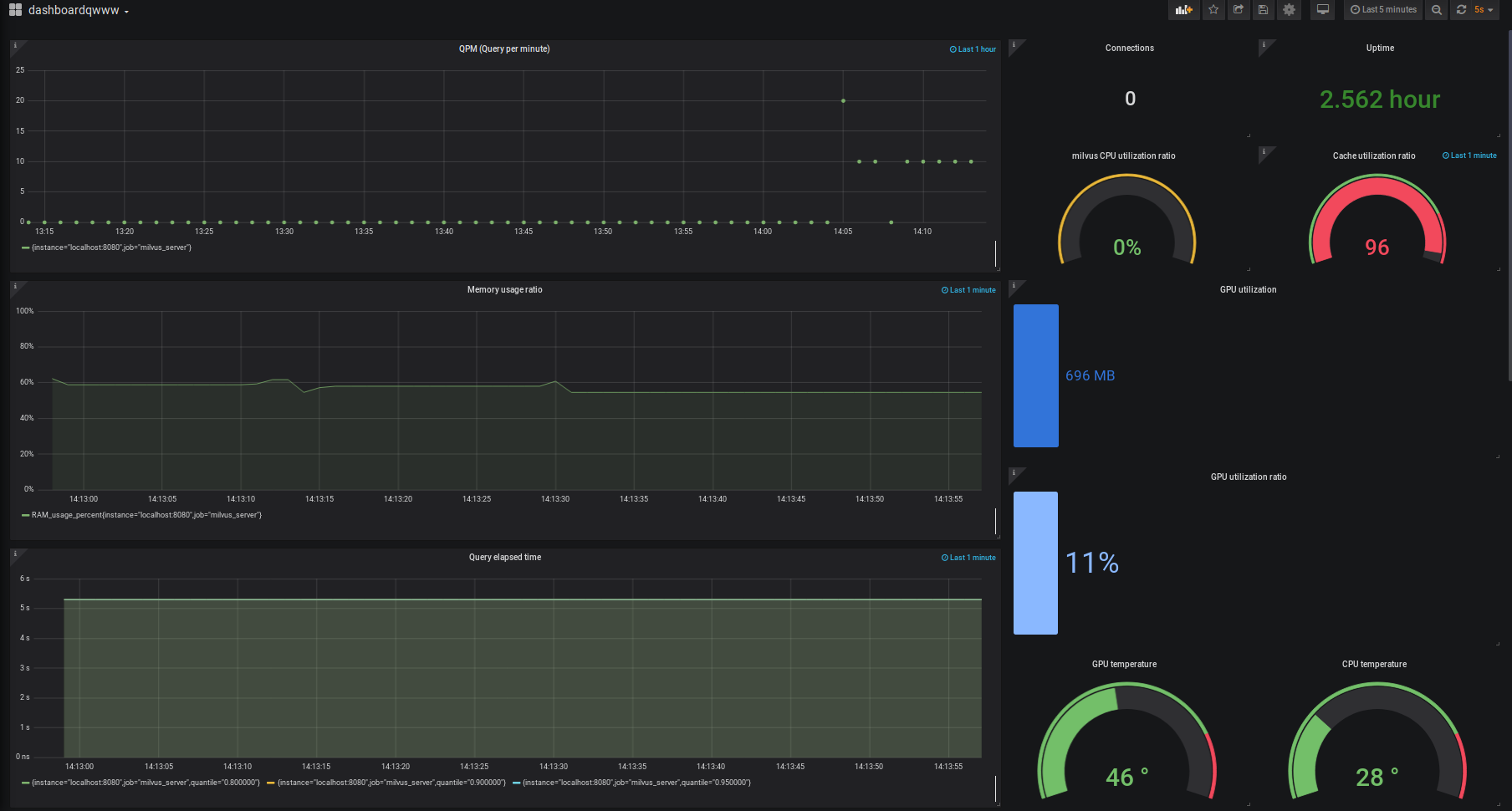
ModaHub魔搭社区:Milvus 监控指标和使用 Grafana 展示 Milvus 监控指标
目录
Milvus 监控指标
Milvus 性能指标
系统运行指标
硬件存储指标 Milvus 监控指标
Milvus 会生成关于系统运行状态的详细时序 metrics。你可以通过 Prometheus、Grafana 或任何可视化工具展现以下指标:
Milvus 性能指标系统运行指标:CPU/GPU 使用…
Windows 和 Anolis 通过 Docker 安装 Milvus 2.3.4
Windows 10 通过 Docker 安装 Milvus 2.3.4 一.Windows 安装 Docker二.Milvus 下载1.下载2.安装1.Windows 下安装(指定好Docker文件目录)2.Anolis下安装 三.数据库访问1.ATTU 客户端下载 一.Windows 安装 Docker
Docker 下载 双击安装即可,安…
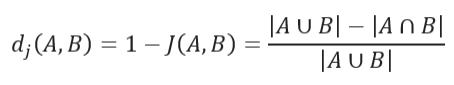
Milvus的相似度指标
官网:https://milvus.io/docs/metric.md版本: v2.3.x
在 Milvus 中,相似度度量用于衡量向量之间的相似度。选择良好的距离度量有助于显着提高分类和聚类性能。下表展示了这些广泛使用的相似性指标如何与各种输入数据形式和 Milvus 索引相匹配。
一、浮…

《向量数据库指南》——Milvus Cloud「日志」问题定位的指南针
“2.X 集群的日志在哪里导啊”“现在没有对 Milvus Cloud 进行任何读写操作,但是日志还是不断增加,这正常吗?”“请教下 k8s 部署的 Milvus Cloud 日志如果持久化,只能使用共享存储吗?如果只想放在本地盘可以如何配置?”
社区讨论问题的时候基本都离不开日志,因为日志…

docker安装Milvus
docker安装Milvus 拉去CPU版本的milvus镜像 $ sudo docker pull milvusdb/milvus:0.10.0-cpu-d061620-5f3c00 docker pull milvusdb/milvus:0.10.0-cpu-d061620-5f3c00
mkdir -p milvus/conf cd milvus/conf ls wget https://raw.githubusercontent.com/milvus-io/milvus/v0.1…

OLAP引擎也能实现高性能向量检索,据说QPS高于milvus!
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 随着 LLM 技术应用及落地,数据库需要提高向量分析以及 AI 支持能力,向量数据库及向量检索等能力“异军突起”,迎来业界持续不断关…
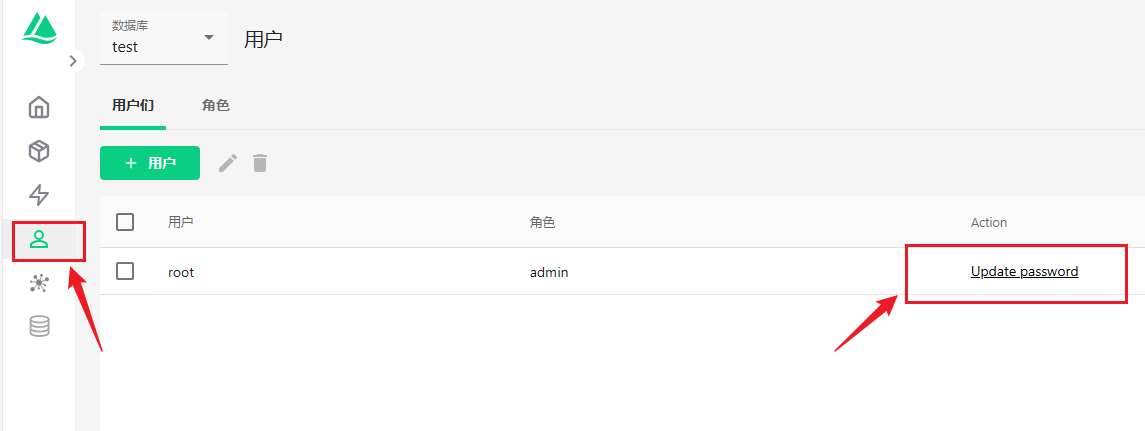
杂记 | 在Linux上使用Docker-compose安装单机版Milvus向量数据库并配置访问控制和可视化面板(Attu)
文章目录 01 Milvus向量数据库简介02 安装前的准备03 安装3.1 创建milvus工作目录3.2 下载并编辑docker-compose.yml3.3 下载milvus.yml文件3.4 启动milvus 04 访问可视化面板并修改密码 01 Milvus向量数据库简介
Milvus是一款开源的向量数据库,它专为AI应用设计&a…
Milvus Standalone安装
使用Docker Compose安装 Milvus standalone(即单机版),进行一个快速milvus的体验。
前提条件:
1.系统可以使用centos
2.系统已经安装docker和docker-compose
3.milvus版本这里选择2.3.1 由于milvus依赖etcd和minio,…
ModaHub魔搭社区:Zilliz Cloud 多组织与角色管理功能,让你的权限管理更简单!
目录
组织与角色功能简介
如何使用组织与角色功能? Zilliz Cloud 云服务是一套高效、高度可扩展的向量检索解决方案。近期,我们发布了 Zilliz Cloud 新版本,在 Zilliz Cloud 向量数据库中增添了许多新功能。其中,用户呼声最高的…
ModaHub魔搭社区:安装、启动 Milvus 服务(GPU版)教程
目录
安装、启动 Milvus 服务
安装前提
操作系统
硬件
软件
确认 Docker 状态
拉取 Milvus 镜像
下载并修改配置文件
启动 Milvus Docker 容器
常见问题
接下来你可以 安装、启动 Milvus 服务
CPU 版 Milvus GPU 版 Milvus
安装前提
操作系统 操作系统 版本 Ce…
Milvus 再上新!支持 Upsert、Kafka Connector、集成 Airbyte,助力高效数据流处理
Milvus 已支持 Upsert、 Kafka Connector、Airbyte! 在上周的文章中《登陆 Azure、发布新版本……Zilliz 昨夜今晨发生了什么?》,我们已经透露过 Milvus(Zilliz Cloud)为提高数据流处理效率, 先后支持了 Up…

milvus-2.3.12安装部署
使用Docker Compose安装 Milvus standalone(即单机版),进行一个快速milvus的体验。 前提条件: 1.系统可以使用centos或者ubuntu 2.系统已经安装docker和docker-compose 3.milvus版本这里使用2.3.12
启动etcd、minio、milvus
由于…

《向量数据库指南》——什么叫“AI 向量数据库”,它和我们日常理解的数据库有什么不同?
我认为"AI 向量数据库"这个概念非常切合实际,它类似于关系数据库在交易领域的作用。个人观点是,向量数据库实际上是为了人工智能而生的。一方面,向量数据库的数据完全源自于人工智能技术。另一方面,对于 AI 应用而言,向量数据库也是至关重要的基础设施。
至于…
Milvus+Attu
Milvus
1.下载
https://github.com/milvus-io/milvus/releases/wget https://github.com/milvus-io/milvus/releases/download/v2.3.0/milvus-standalone-docker-compose.yml下载milvus-standalone-docker-compose
version: 3.5services:etcd:container_name: milvus-etcdim…

《向量数据库指南》——AI 热潮中的非典型Milvus Cloud向量数据库
2023 年是 AI 应用开发领域的一个重要转折点。
在这一年里,大语言模型(LLMs)因其卓越的自然语言处理能力而广受赞誉,极大地拓宽了机器学习应用的场景。开发者们逐渐意识到,有了 LLMs,他们可以设计出更智能、更容易互动的应用程序。与此同时,“向量数据库”已成为业界…

《向量数据库指南》——AutoGPT 宣布不再使用向量数据库
生成式 AI 促进了向量数据库的火爆,但如今的技术风向变化似乎也挺快。作为全球最著名的 AI 项目之一,AutoGPT 宣布不再使用向量数据库,这一决定可能让不少人感到惊讶。毕竟从一开始,向量数据库就一直协助管理着 AI 智能体的长期记忆。
那么这个基本设计思路怎么就变了?又…

《向量数据库指南》——亚马逊云科技向量数据库揭秘:点亮数据未来!
在我们讨论亚马逊云科技向量数据库之前,我们必须先搞懂向量数据库。 那么,向量数据库是什么呢?简单来说,向量数据库就是一种专门用于处理和查询向量数据的数据库。与传统数据库以表格形式组织和存储数据不同,向量数据库采用多维数值数组的形式处理和存储数据。它的主要目标…

成功安装Milvus!零基础Ubuntu部署安装Milvus教程
Milvus源码编译安装 Milvus源码编译安装Golang和C开发环境安装源码安装编译基础依赖:OpenBLAS安装Rust安装前置依赖下载源码更改安装脚本开始编译测试Milvus是否安装成功 遇到的问题问题1:问题2:问题3:问题4:问题5&…
ModaHub魔搭社区:详解向量数据库Milvus的Mishards:集群分片中间件(三)
目录
链路追踪
日志
路由 链路追踪
分布式系统错综复杂,请求往往会分发给内部多个服务调用。为了方便问题的定位,我们需要跟踪内部的服务调用链。系统的复杂性越高,一个可行的链路追踪系统带来的好处就越明显。我们选择了已进入 CNCF 的 …
如何在维格云中自动新增一行或多行数据?
简介
在日常使用维格云中,通常会出现一张表中有数据发生变化时,需要另一张表同时新增一些数据,比如: 项目管理中,每新增一个项目,都要在任务表中产生若干个固定的任务;或一个任务要自动生成若干子任务当一笔订单状态变为成交后,可能要在客户成功表中新增一行记录;帮…
源码部署Milvus(三)成功解决vscode调试milvus源码时间超时问题!
作者有话说
继上周成功调试后出现时间超时问题,且想定位create_index等如何触发milvus底层实现文件,总是报错Timeout,这周碎片化抽空解决此问题,猜测可能是vscode配置的调试环境有问题,果不其然!
报错
g…
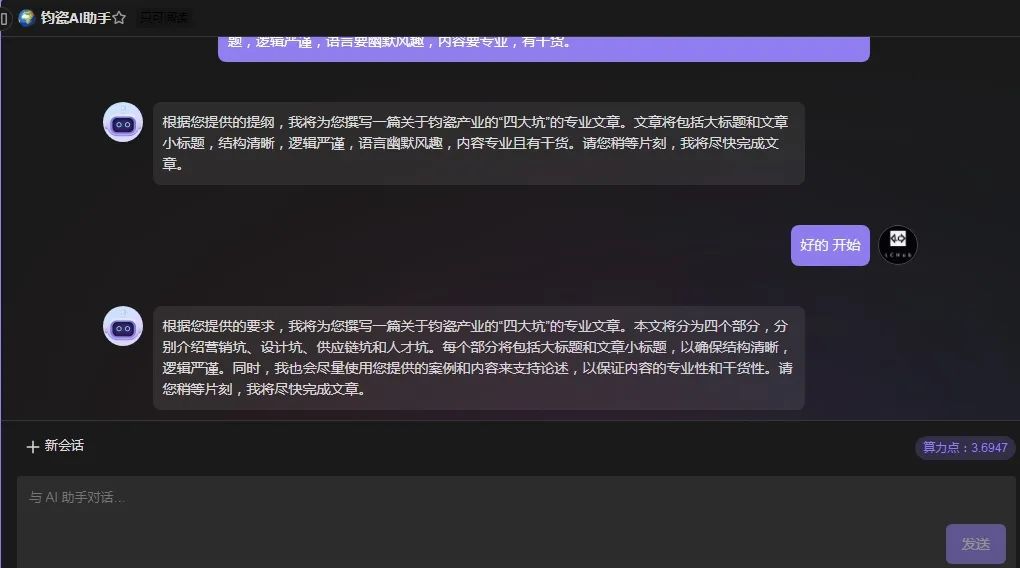
如何用维格云搭建和一键训练你的钧瓷AI机器人?
大禹智库
第69期(总第400期) 2023年11月4日 如何用维格云搭建和一键训练你的钧瓷AI机器人?
钧瓷私有数据聊天机器人是一种能够根据预设的数据集进行智能对话的机器人。通过维格云,我们可以轻松地搭建自己的钧瓷私有数据聊天机器人。本文将以钧道机器人为例,详细介绍如何…
《向量数据库指南》——向量数据库Milvus Cloud快速打造知识库 AI 应用
快速打造知识库 AI 应用 具备知识库的 AI Chatbot 已然是当下基于大模型技术实现及应用最多的情景,接下来,我们将以制作一个具备 Dify 产品及团队知识背景的 AI 应用为例,为大家介绍如何从零开始,用 3 步搭建一个具备企业知识库的 AI 应用。 平台注册 在本次实操演示中,我…

docker compose安装milvus
下载对应版本的milvus-standalone-docker-compose.yml wget https://github.com/milvus-io/milvus/releases/download/v2.3.5/milvus-standalone-docker-compose.yml重新命令为docker-compose.yml
mv milvus-standalone-docker-compose.yml docker-compose.yml启动milvus
doc…
AIGC|如何将Milvus集成到LangFlow中?详细代码演示!
目录
一、基本介绍
二、修改langflow代码使其支持milvus
三、效果演示 langflow是一个LangChain UI,它提供了一种交互界面来使用LangChain,通过简单的拖拽即可搭建自己的实验、原型流。通过在langflow中引入Milvus,用户可以更方便地存储和…

《向量数据库》——向量数据库Milvus 和大模型出联名款AI原生Milvus Cloud
大模型技术的发展正加速对千行百业的改革和重塑,向量数据库作为大模型的海量记忆体、云计算作为大模型的大算力平台,是大模型走向行业的基石。而电商行业因其高度的数字化程度,成为打磨大模型的绝佳“战场”。 在此背景下,Zilliz 联合亚马逊云科技举办的【向量数据库 X 云计…

用AI + Milvus Cloud搭建着装搭配推荐系统
在上一篇文章中,我们学习了如何利用人工智能技术(例如开源 AI 向量数据库 Milvus Cloud 和 Hugging Face 模型)寻找与自己穿搭风格相似的明星。在这篇文章中,我们将进一步介绍如何通过对上篇文章中的项目代码稍作修改,获得更详细和准确的结果,文末附赠彩蛋。 注:试用此…
milvus数据管理-压缩数据
Milvus 默认支持自动数据压缩。您可以 配置 Milvus 以启用或禁用 压缩 和自动压缩。 如果自动压缩被禁用,您仍然可以手动压缩数据。
1.手动压缩数据 压缩请求是异步处理的,因为它们通常需要花费很长时间。
from pymilvus import Collection
collection…
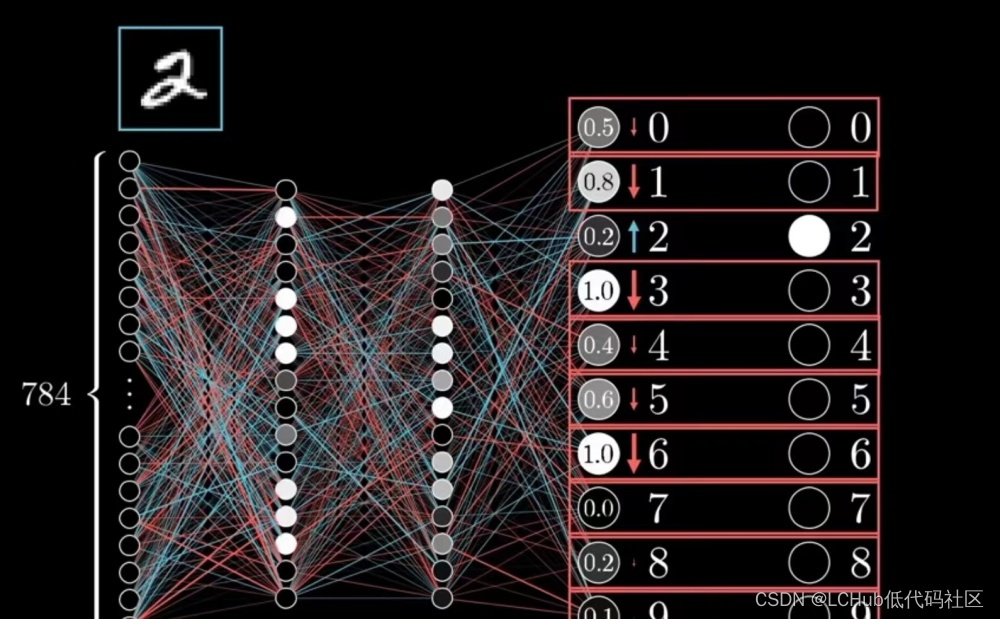
《向量数据库指南》——宏观解读向量数据库Milvus Cloud
宏观解读向量数据库 如今,强大的机器学习模型配合 Milvus 等向量数据库的模式已经为电子商务、推荐系统、语义检索、计算机安全、制药等领域和应用场景带来变革。而对于用户而言,除了足够多的应用场景,向量数据库还需要具备更多重要的特性,包括: 可灵活扩展、支持调参:当…

用向量数据库Milvus Cloud搭建检索知识库机器人
检索知识库 Milvus 中已经存储了文本块向量,现在可以进行向量查询了。 以下函数创建了 1 个查询 pipeline。注意,这是本教程中最为关键的一个步骤! ops.ann_search.osschat_milvus(host=MILVUS_HOST, port=MILVUS_PORT, **{metric_type: IP, limit: 3, output_fields: [text…
《向量数据库指南》——用 Milvus Cloud和 NVIDIA Merlin 搭建高效推荐系统结论
如何搭建一个高效的推荐系统? 简单来说,现代推荐系统由训练/推理流水线(pipeline)组成,涉及数据获取、数据预处理、模型训练和调整检索、过滤、排名和评分相关的超参数等多个阶段。走遍这些流程之后,推荐系统能够给出高度个性化的推荐结果,从而提升产品的用户体验。
为…

向量数据库Transwarp Hippo1.1多个新特性升级,帮助用户实现降本增效
例如,当查询“A公司业务发展情况”时,通过向量检索可以检索出A公司“主要业务”、“经营模式”、“财务情况”、“市场地位”等信息,通过全文检索可以检索出知识库中和关键字“业务”、“发展”相关的结果作为补充,通过将两者检索的结果进行结合,可以使得大模型回答的结果…
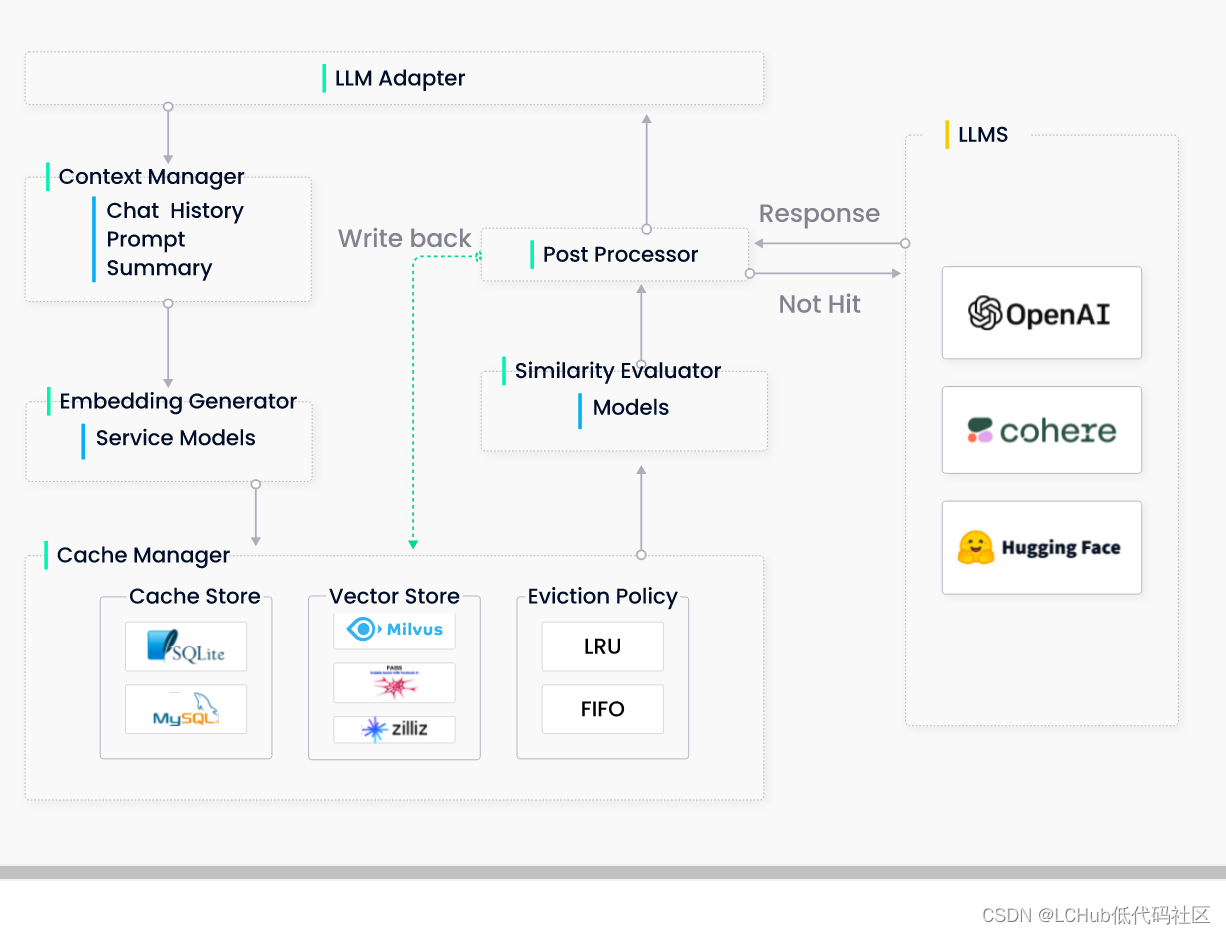
ModaHub魔搭社区:GPTCache的工作原理和为什么选择 GPTCache?
什么是 GPTCache?
GPTCache 是一个开源工具,旨在通过实现缓存来提高基于 GPT 的应用程序的效率和速度,以存储语言模型生成的响应。GPTCache 允许用户根据其需求自定义缓存,包括嵌入函数、相似度评估函数、存储位置和驱逐等选项。…
用 LangChain 和 Milvus 从零搭建 LLM 应用
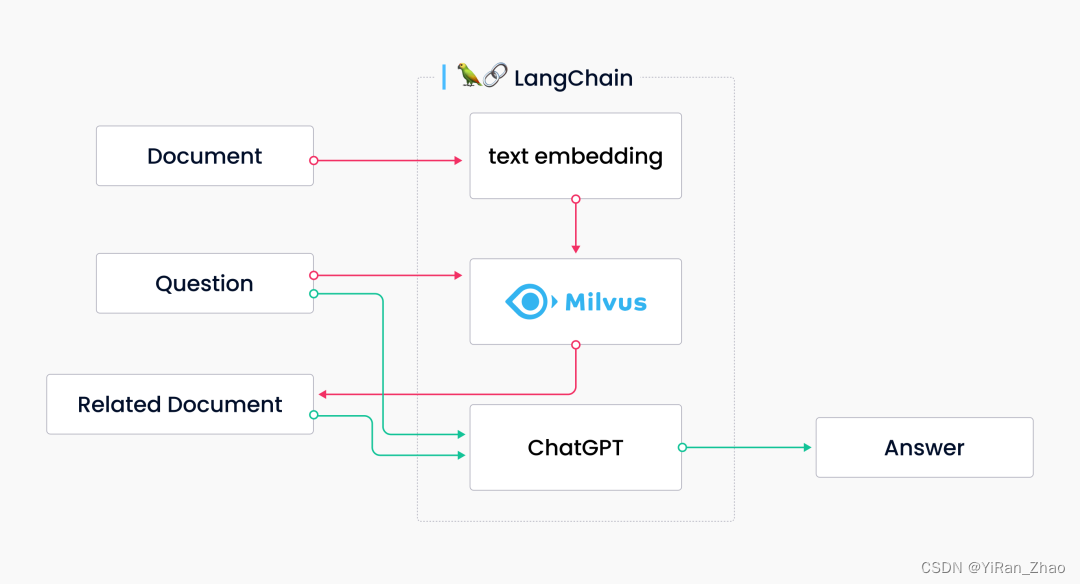
如何从零搭建一个 LLM 应用?不妨试试 LangChain Milvus 的组合拳。
作为开发 LLM 应用的框架,LangChain 内部不仅包含诸多模块,而且支持外部集成;Milvus 同样可以支持诸多 LLM 集成,二者结合除了可以轻松搭建一个 LL…

向量数据库:Milvus
特性 Milvus由Go(63.4%),Python(17.0%),C(16.6%),Shell(1.3%)等语言开发开发,支持python,go,java接口(C,Rust,c#等语言还在开发中),支持单机、集群部署,支持CPU、GPU运算。Milvus 中的所有搜索和查询操作都在内存中执行…

在minkube上部署Milvus
Milvus
Milvus是一个向量数据库,可以为ai做数据支撑。
Preparatory Work
minikube
minikube是一款微型本地k8s
install
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64sudo install minikube-linux-amd64 /usr/loca…

Milvus数据库介绍
参考:https://www.xjx100.cn/news/1726910.html?actiononClick
Milvus 基于FAISS、Annoy、HNSW 等向量搜索库构建,核心是解决稠密向量相似度检索的问题。在向量检索库的基础上,Milvus 支持数据分区分片、数据持久化、增量数据摄取、标量向量…
云原生向量数据库Milvus
什么是 Milvus
Milvus 是一款云原生向量数据库,它具备高可用、高性能、易拓展的特点,用于海量向量数据的实时召回。
Milvus 基于 FAISS、Annoy、HNSW 等向量搜索库构建,核心是解决稠密向量相似度检索的问题。在向量检索库的基础上ÿ…

milvus insert数据在s3的存储
insert数据在s3的存储
对segment进行flush操作,会将数据持久化至s3对象存储。
相关核心代码位置:
ibNode.flushManager.flushBufferData()主要代码在flushBufferData()函数。
代码位置:internal\datanode\flush_manager.go
// flushBufferData notifies flush …

ModaHub魔搭社区:向量数据库Milvus性能优化问题(二)
目录
为什么有时候小的数据集查询时间反而更长?
为什么查询时 GPU 一直空闲?
为什么数据插入后不能马上被搜索到?
为什么我的 CPU 利用率始终不高?
创建集合时 index_file_size 如何设置能达到性能最优? 为什么有…

《向量数据库指南》——开源框架NVIDIA Merlin 向量数据库Milvus
NVIDIA Merlin & Milvus 推荐系统 pipeline 中至关重要的一环便是为用户检索并找到最相关的商品。为了实现这一目标,通常会使用低维向量(embedding)表示商品,使用数据库存储及索引数据,最终对数据库中数据进行近似最近邻(ANN)搜索。这些向量表示是通过深度学习模型获…

大禹智库:下一代向量数据库————具备在线化,协作化,可视化,自动化和安全互信的向量数据库
目录
一、在线化
二、协作化
三、可视化
四、自动化
五、安全互信
结论: 行业分析报告:下一代向量数据库的特征 摘要:
向量数据库是一种用于存储和处理向量数据的数据库系统。随着人工智能和大数据技术的快速发展,向量数据…

语义检索系统【全】:基于milvus语义检索系统指令全流程-快速部署版
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源) 专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术…
向量数据库Milvus字符串查询
因为项目需要,用到了向量数据库Milvus,刚开始都没有遇到问题,直到一个表的主键是字符串(VARCHAR),在查询时刚好要以该主键作为查询条件,此时会出现异常,特此记录一下。 记住…

《向量数据库指南》——选择向量数据库时需要考量的点Milvus Cloud
大禹智库:选择向量数据库时需要考量的点 性能 如上述,查询性能(查询的响应时间,系统的吞吐能力)是在选型向量数据库时的一个重要参考点,市面上现有的向量数据库的 Benchmark 有: ANN-Benchmark 是一种用于评估各种向量数据库和近似最近邻(ANN)算法性能的工具 VectorD…
RAG 新路径!提升开发效率、用户体验拉满
RAG(Retrieval-Augmented Generation)框架结合了强大的信息检索能力和生成模型的能力,允许系统从海量数据中检索相关信息,并基于这些信息生成准确、丰富的回答。随着大语言模型和智能问答技术的崛起,RAG 凭借其独特的结…
为AI而生的数据库:Milvus详解及实战
1 向量数据库
1.1 向量数据库的由来
在当今数字化时代,人工智能AI正迅速改变着我们的生活和工作方式。从智能助手到自动驾驶汽车,AI正在成为各行各业的创新引擎。然而,这种AI的崛起也带来了一个关键的挑战:如何有效地处理和分析…

milvus采坑一:启动服务就会挂掉
原因一
硬盘满了,Eric数据文件存储在硬盘上,当硬盘不足,它就会启动后就挂掉。 此时pymilvus连接一直是timeout。
解决方法:更换存储路径。
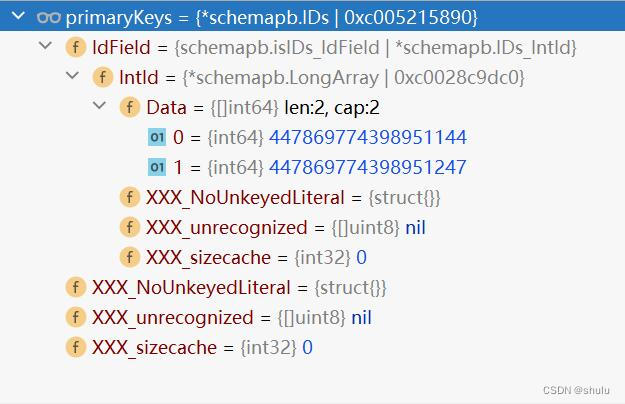
milvus Delete API流程源码分析
Delete API执行流程源码解析
milvus版本:v2.3.2
整体架构: Delete 的数据流向: 1.客户端sdk发出Delete API请求。
from pymilvus import (connections,Collection,
)print("start connecting to Milvus")
connections.connect("default", host"192…
milvus安装及langchain调用
milvus安装及langchain调用 安装milvus安装docker-compose安装milvus安装可视化界面attu 通过langchain调用milvus安装langchain安装pymilvus调用milvus 安装milvus
安装docker-compose
下载文件
curl -L https://github.com/docker/compose/releases/download/1.21.1/docke…
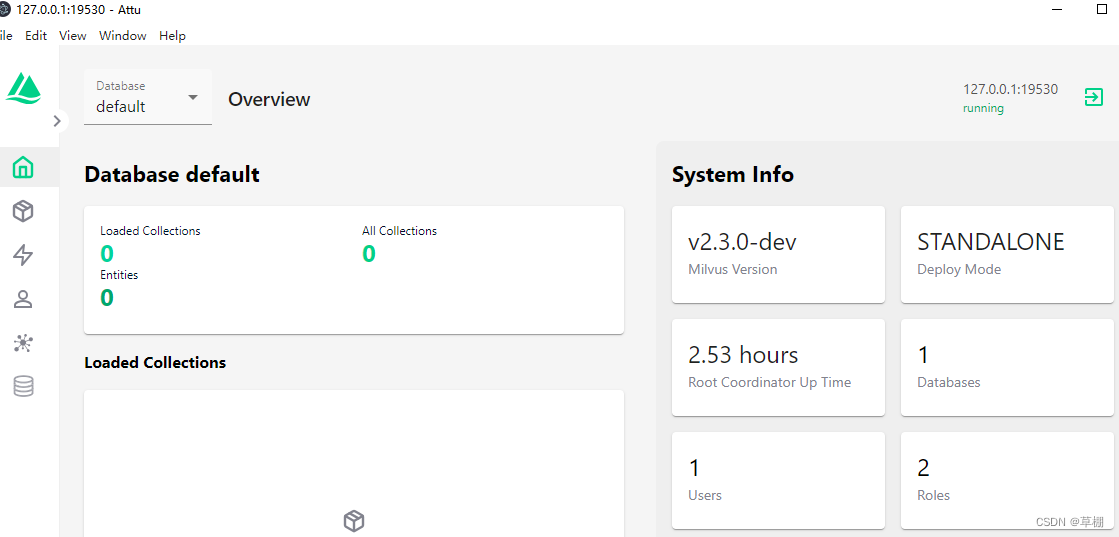
windows安装向量数据库milvus
本文介绍windows下安装milvus的方法。
一.Docker安装
1.1docker下载
首先到Docker官网上下载docker:Docker中文网 官网 1.2.安装前前期准备
先使用管理员权限打开windows powershell 然后在powershell里面输入下面那命令,启用“适用于 Linux 的 Windows 子系统”…
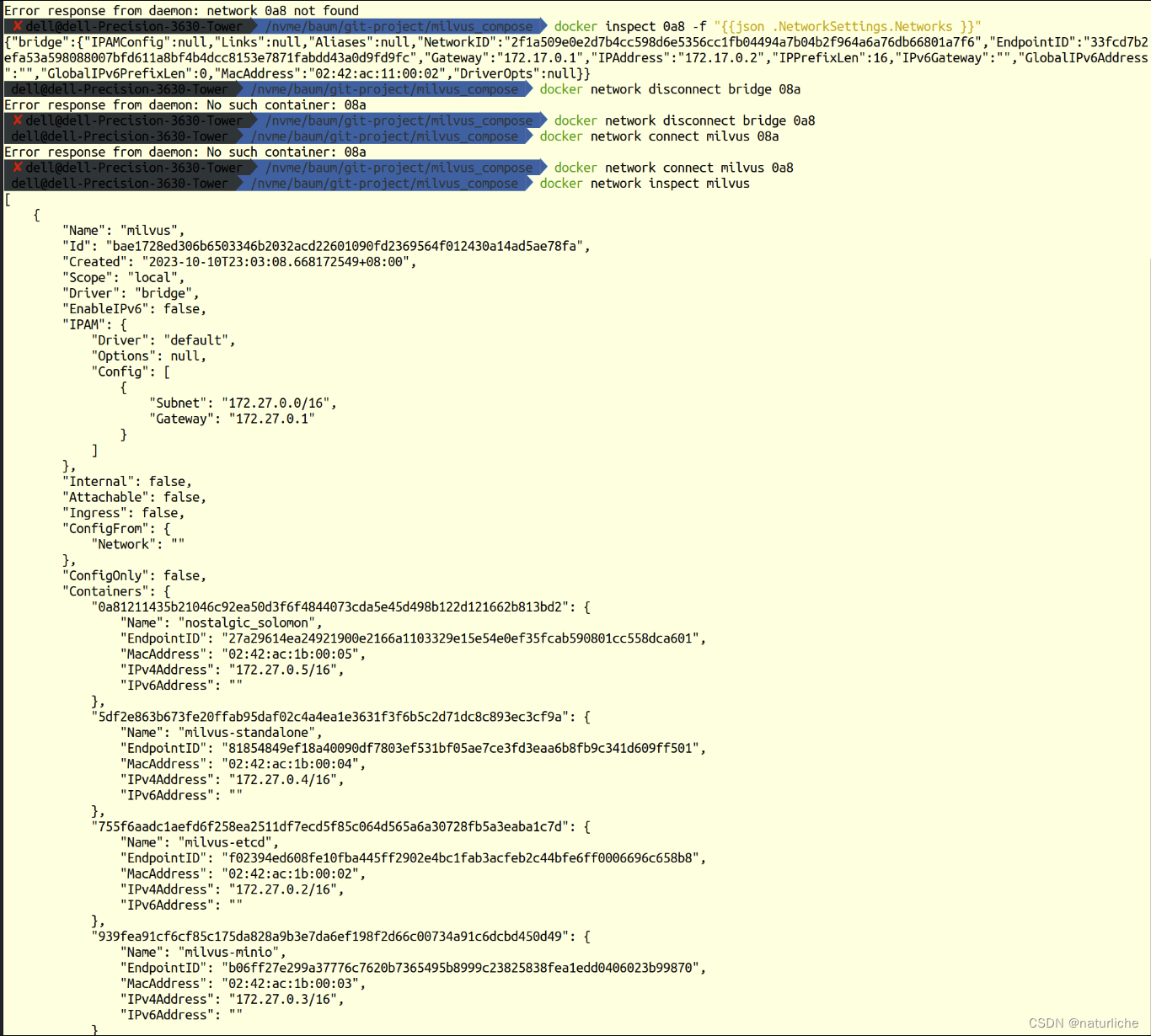

在LangChain中使用Milvus + openai使用
Milvus(opens in a new tab) 是一个存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大规模嵌入向量的数据库。
1.文档分割
from langchain.document_loaders import PyPDFLoader
pdfloader PyPDFLoader("D:\py\LangChaindao\操作系统原理.pdf&…
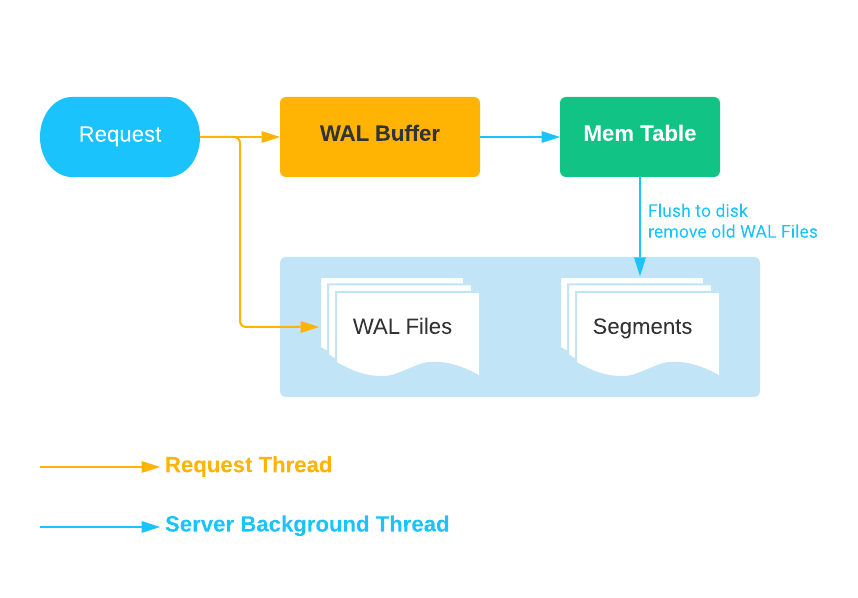
ModaHub ——向量数据库Milvus特征向量和预写式日志教程
目录
特征向量
什么是特征向量
特征向量的优势
应用领域
预写式日志
数据可靠性
缓冲区设置
旧日志删除 特征向量
什么是特征向量
向量是具有一定大小和方向的量,可以简单理解为一串数字的集合,就像一行多列的矩阵,比如:…

milvus upsert流程源码分析
milvus版本:v2.3.2
整体架构: Upsert 的数据流向: 1.客户端sdk发出Upsert API请求。
import numpy as np
from pymilvus import (connections,Collection,
)num_entities, dim 4, 3print("start connecting to Milvus")
connections.connect("default",…

《向量数据库指南》——AIGC 需求的快速变化,催生了Milvus Cloud向量数据库的超高速迭代
对于“版本”成为热度排名第一的关键词,我开始是有点意外的,仔细一想似乎也在情理之中。2023年,是 AIGC 大爆发的一年,LLM 展现出了强大的分析、推理、归纳、总结能力。但是,由于缺乏最新的和特定领域的训练数据,大模型“幻觉”成为困扰 AIGC 开发者的一大难题。随着 RAG…
RAG +milvus示例
GitHub - NVIDIA/DeepLearningExamples: State-of-the-Art Deep Learning scripts organized by models - easy to train and deploy with reproducible accuracy and performance on enterprise-grade infrastructure. Towhee GitHub Zilliz GitHub
docker-compose部署milvus
部署milvus
上一篇介绍了使用kubernetes来部署milvus,这篇介绍下使用docker-compose来部署milvus。 下载docker-compose
docker-compose的Github地址https://github.com/docker/compose/releases下载最新版的 docker-compose-linux-x86_64 在服务器上使用
wget …

《向量数据库指南》——向量数据库Milvus Cloud如何面对市场质疑?
我认为答案是这样:如果你的数据量只有 100 万条或者几十万条,无论使用何种数据库都可以解决这个问题,甚至不用使用向量数据库也可以达到目标。就像为什么要使用 MySQL 一样,如果你只有 100 条数据,可能在 Excel 中进行…
《向量数据库指南》——向量数据库Milvus Cloud如何面对市场质疑?
我认为答案是这样:如果你的数据量只有 100 万条或者几十万条,无论使用何种数据库都可以解决这个问题,甚至不用使用向量数据库也可以达到目标。就像为什么要使用 MySQL 一样,如果你只有 100 条数据,可能在 Excel 中进行…

milvus 结合Thowee 文本转向量 ,新建表,存储,搜索,删除
1.向量数据库科普
【上集】向量数据库技术鉴赏 【下集】向量数据库技术鉴赏 milvus连接
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
connections.connect(host124.****, port19530)2.milvus Thowee 文本转向量 使用 …

《向量数据库指南》——AI原生向量数据库Milvus Cloud 2.3架构升级
架构升级 GPU 支持 早在 Milvus 1.x 版本,我们就曾经支持过 GPU,但在 2.x 版本中由于切换成了分布式架构,同时出于对于成本方面的考虑,暂时未加入 GPU 支持。在 Milvus 2.0 发布后的一年多时间里,Milvus 社区对 GPU 的呼声越来越高,再加上 NVIDIA 工程师的大力配合——为…
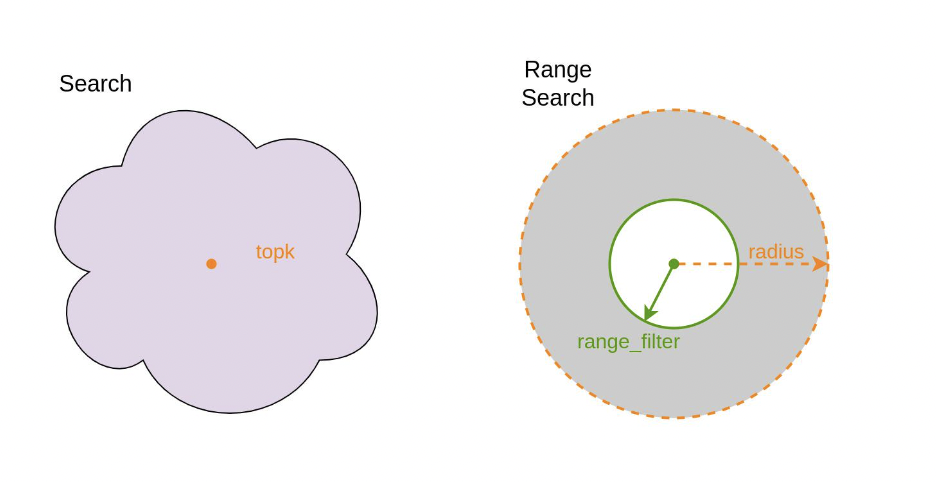
《向量数据库指南》——什么是 向量数据库Milvus Cloud的Range Search?
Range Search 功能诞生于社区。
某天,一位做系统推荐的用户在社区提出了需求,希望 Milvus Cloud 能提供一个新功能,可以返回向量距离在一定范围之内的结果。而这不是个例,开发者在做相似性查询时,经常需要对结果做二次过滤。
为了帮助用户解决这一问题,Milvus Cl…

《向量数据库》——Milvus v1.0 已发布
Milvus v1.0 已发布
今天,我们很高兴地宣布 Milvus v1.0 版本的发布。通过数百名 Milvus 社区用户在八个月内不断的测试和试验, Milvus v0.10.x 现在已足够稳定,是时候该发布基于 Milvus v0.10.6 的 Milvus v1.0 了。
Milvus v1.0 具有以下功能: 支持主流的相似度计算方式…

《向量数据库指南》——向量数据库Weaviate Cloud 特性对比
随着以 Milvus 为代表的向量数据库在 AI 产业界越来越受欢迎,传统数据库和检索系统也开始在快速集成专门的向量检索插件方面展开角逐。 例如 Weaviate 推出开源向量数据库,凭借其易用、开发者友好、上手快速、API 文档齐全等特点脱颖而出。同样,Zilliz Cloud/Milvus 向量数据…

《向量数据库指南》——最实用的 Milvus 迁移手册
毫无疑问,Milvus 已经成为全球诸多用户构建生产环境时必不可少的向量数据库。 近期,Milvus 发布了全新升级的 Milvus 2.3 版本,内核引擎加速的同时也加入了诸如支持 GPU 这样实用且强大的特性。可以说,以 Milvus 2.3 为代表的 Milvus 2.x 版本无论在功能还是性能上都远超 M…
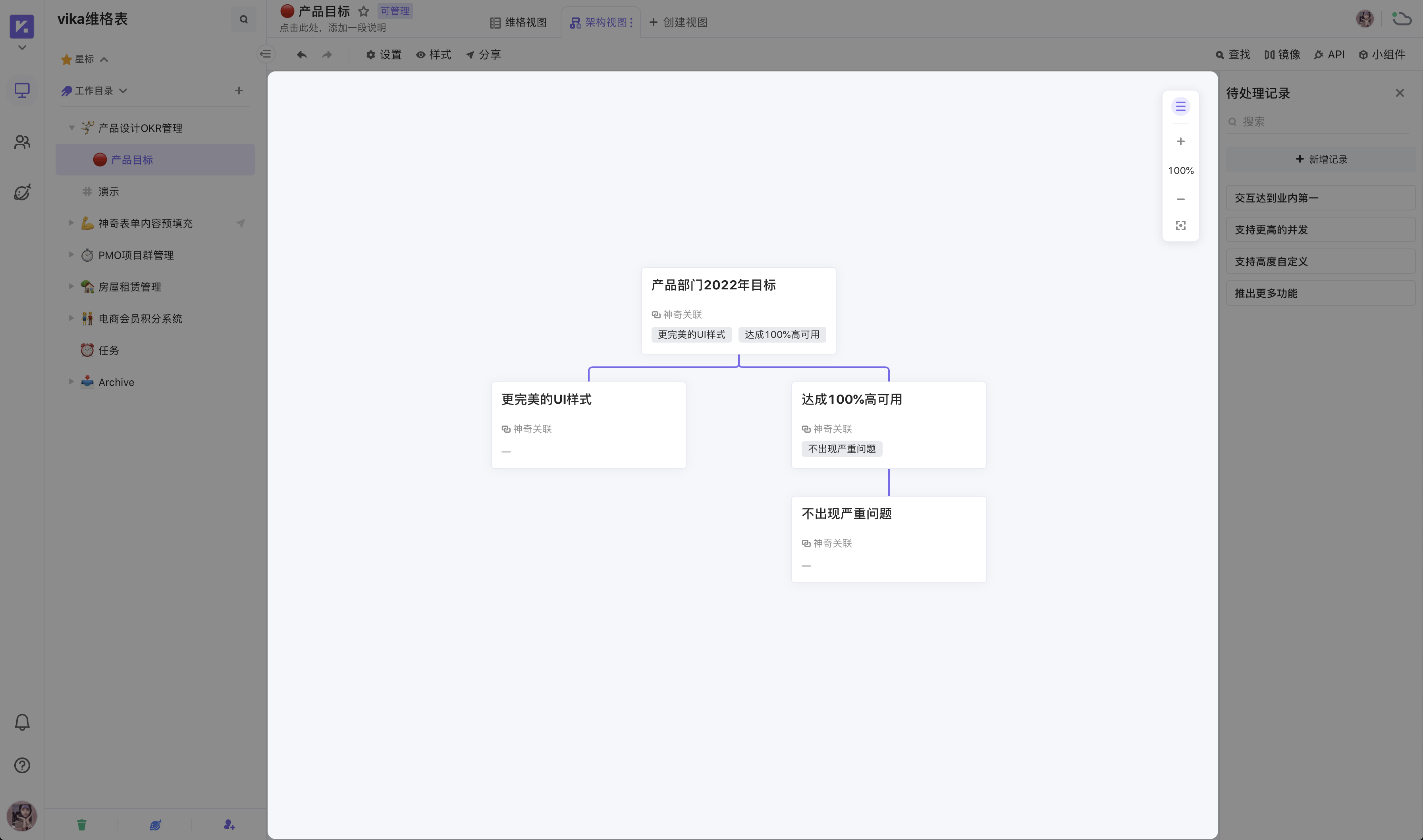
《低代码指南》——AI低代码维格云架构视图怎么用?
架构视图是一个展示信息层级关系的视图,轻轻拖拽卡片,就能搭建精巧缜密的企业组织架构视图、实现信息结构化。 利用好架构视图,可以很好地解决以下场景: 展示企业/团队的组织关系 可视化管理产品开发架构 统筹全员 OKR 完成情况 架构视图的基础知识
架构视图分为以下几个…

大模型时代和传统机器学习时代工具栈侧重点有所不同
大模型时代和传统机器学习时代工具栈侧重点有所不同
本章从企业训练模型、构建AI赋能应用的工作流视角出发,详解涉及的主要环节,并关注LLMOps和MLOps在流程上的侧重点差异。我们认为AI = Data + Code,历经数据准备、模型训练、模型部署、产品整合,分环节看:
► 数据准…

《向量数据库指南》——Range Search 的技术实现细节
Range Search 功能诞生于社区。
某天,一位做系统推荐的用户在社区提出了需求,希望 Milvus Cloud 能提供一个新功能,可以返回向量距离在一定范围之内的结果。而这不是个例,开发者在做相似性查询时,经常需要对结果做二次过滤。
为了帮助用户解决这一问题,Milvus Cl…
Milvus的向量索引(内存索引)
版本: v2.3.x官网: https://milvus.io/docs/index.md
一、简介
Milvus 支持的各种类型的内存索引、每种索引最适合的场景以及用户可以配置以获得更好搜索性能的参数。索引是有效组织数据的过程,它通过显着加速大型数据集上耗时的查询,在使相似性搜索变…

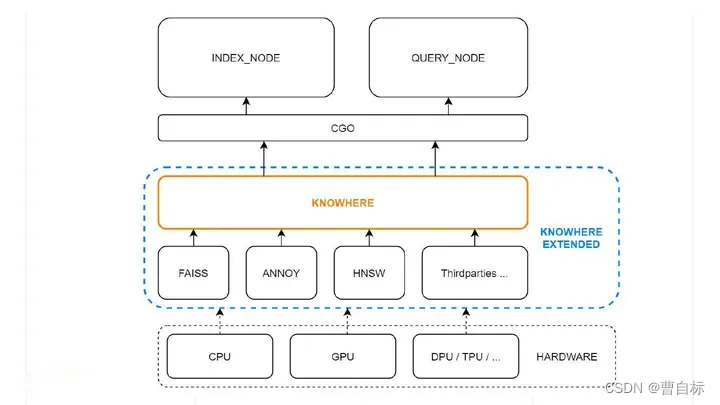
milvus knowhere源码编译测试
简介
Knowhere 是 Milvus 的核心向量执行引擎,集成了Faiss、Hnswlib和Annoy等多个向量相似度搜索库。
编译环境
操作系统: Ubuntu 22.04.4
gcc/g:11.4.0
cmake: 3.27.7
安装依赖
apt install build-essential libopenblas-dev libaio-dev python3-dev python…